
Go GC
Go는 메모리 관리를 런타임에서 해주는 프로그래밍 언어이다. 메모리 관리라고 하면 일반적으로 힙 영역에 할당하는 메모리들 더이상 스택에서 접근할 수 없는 상태가 되면, 할당 해제하는 가비지 콜렉팅을 의미한다. 이번 글에서는 GC에 대한 전반적인 이야기와 함께, Go에서는 구체적으로 어떤지 알아보았다.
💡 우선 글은 1.17 버전의 코드를 보면서 작성되었다.
💡 글에서GC라는 말은 “가비지 콜렉터”를 의미하기도 하고 “가비지 콜렉터의 동작”을 의미하기도 한다. 동사로 사용되었으면 콜렉터의 동작, 명사면 콜렉터라고 이해하면 좋을 것 같다.
흔히 알려진 설명
GC에 대한 아주 개략적인 Overview이다. 현대 많은 언어는 GC와 함께 메모리 관리를 도와주고 있다. 일반적으로 프로그램에서 동적 할당을 하게 되면 프로세스의 힙(Heap) 영역에 메모리를 할당하게 되어있다.
1 | Person p = new Person(); // 힙 사용 |
이때, 힙 영역에 할당된 메모리를 할당 해제 해줘야 하는데, 이 과정을 개발자가 직접 하는 경우가 있고, 언어의 런타임 레벨에서 자동으로 해주는 경우가 있다. 이때 자동으로 해주는 컴포넌트의 이름이 GC이다.
GC는 대략 다음과 같은 흐름을 갖는다.
- GC 수행 시간 동안 GC 스레드를 제외하고 모든 스레드 정지
- GC는 참조할 수 없는 객체를 확인하고 메모리 할당 해제
- GC가 끝난 후 정지된 애플리케이션 스레드를 다시 재개
1번의 정지되는 순간을 STW (Stop The World)라고 부른다. 이때 STW가 발생하는 순간은 GC 수행의 전체 과정이 아닐 수 있다. 어떤 알고리즘을 사용하는지에 따라 어떤 구간에서 STW가 발생할지 달라진다. 아무튼 GC가 발전하는 과정은 이 STW 시간을 줄이는 과정이고 GC를 튜닝하는 이유도 대부분 STW를 줄이기 위함이다.
알려진 방법들
GC의 핵심적인 동작을 수행하는 두 가지 알고리즘을 가져왔다. 첫 번째는 Mark & Sweep 방식이고, 두 번째는 Reference Counting이다.
Mark & Sweep
이름이 아주 직관적인데, 말 그대로 지워야 하는 오브젝트를 마킹하고 청소하는 방법이다. 스택에서 힙을 참조하고 있는 루트 포인터를 찾아서 해당 루트 노드부터 체이닝 하면서 접근할 수 있는 오브젝트를 제거 대상에서 제외한다. 모두 순회하고 나서는 아직 제거 대상에 있는 오브젝트를 할당 해제하는 방식이다. Go와 JVM, JS에서 이 알고리즘을 사용한다.
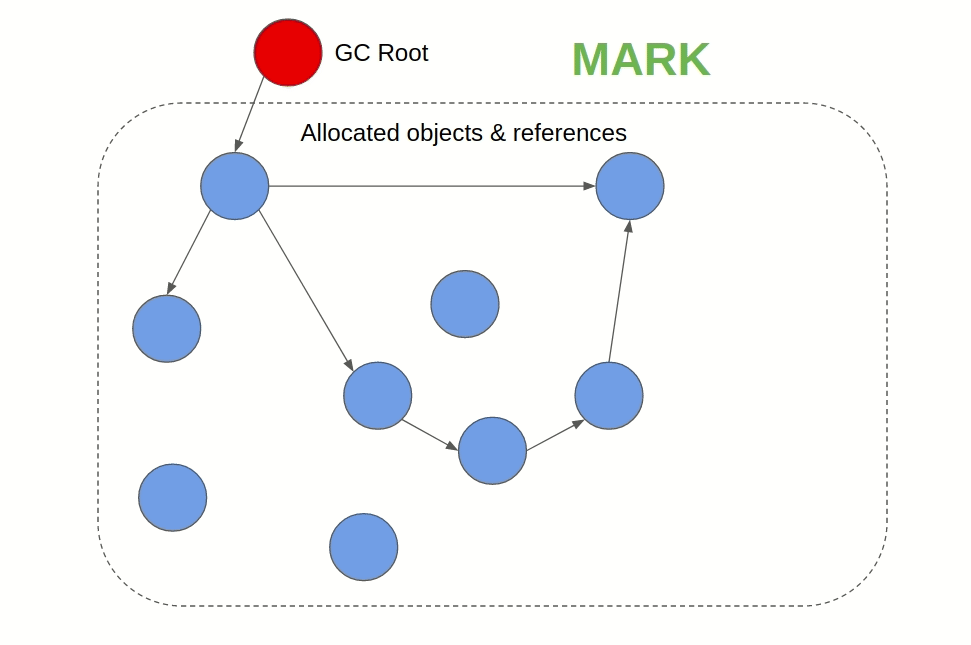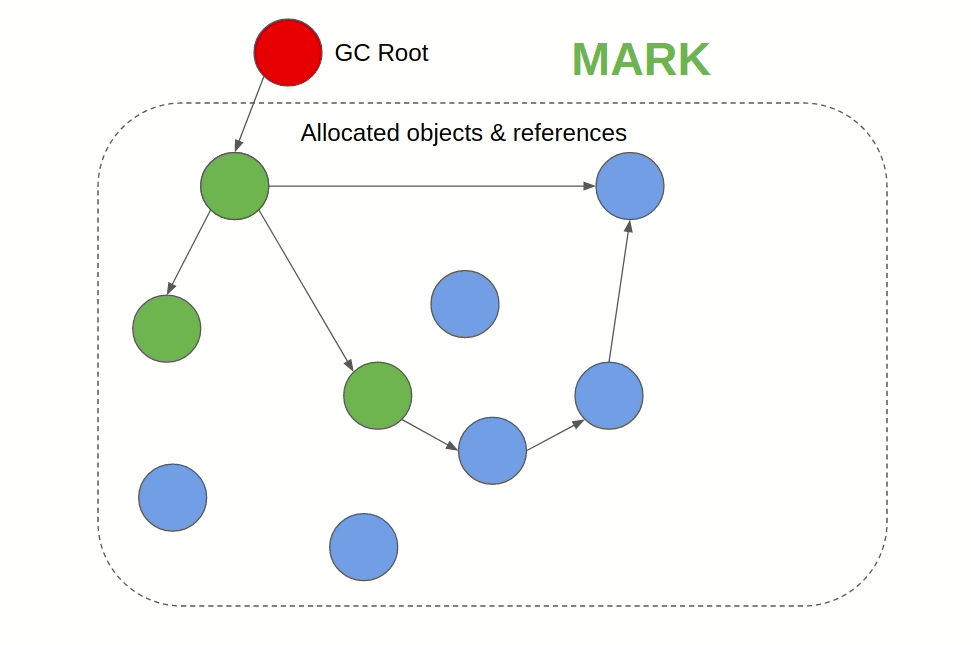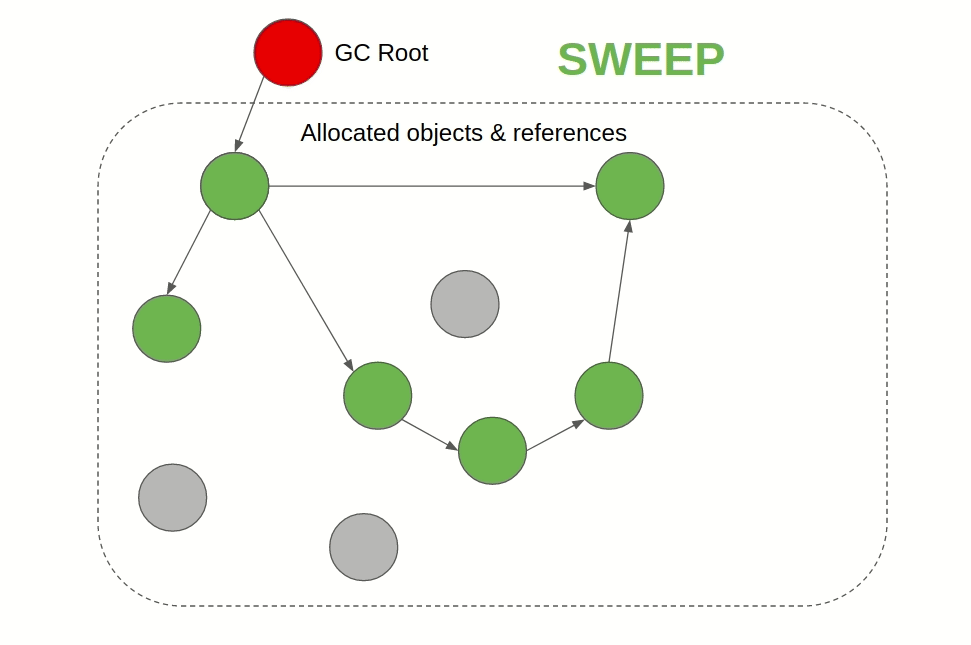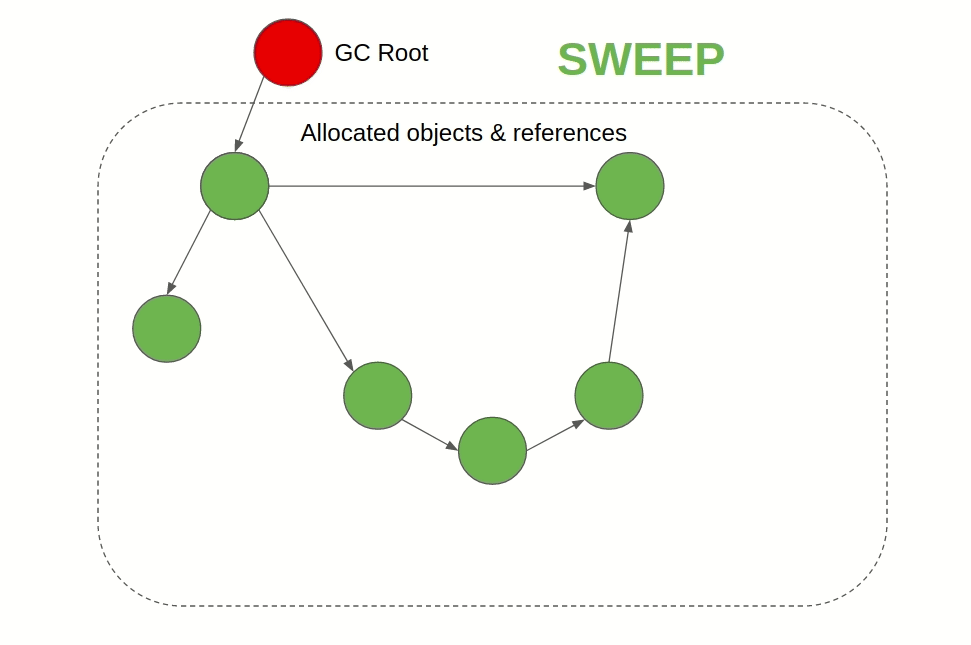
이미지 출처: 링크
Reference Counting
모든 오브젝트들이 참조 횟수 카운터를 갖고, 카운터가 0이 되는 오브젝트를 GC가 지우는 방식이다. 이 방법은 Python, PHP에서 사용 중인데, 근본적으로 순환 참조하고 있는 오브젝트에 대한 GC가 이루어질 수 없다. 이를 처리하기 위한 추가적인 컴포넌트와 함께 동작해야 한다.
여기 링크에서 여러 GC들의 할당과 해제 모습을 시각화해서 보여주고 있다. 여기 작성된 알고리즘 외, 추가로 몇 가지가 더 설명되어 있으니 궁금하다면 위에서 간략하게 소개된 방법들에 대해 알아보면 좋을 것 같다.
GC를 구성하는 것들
아! Go, JVM, JS는 Mark & Sweep! 끄덕 끄덕, 하고 끝나면 좋겠지만 편한 프로그래밍의 뒷면은 그렇게 단순하지는 않다. 위에서 “알려진 방법들“로 소개한 방법들은 핵심적인 콜렉터의 동작 알고리즘에 관한 내용이고, GC를 구현한 언어에 따라 추가적인 기술이나 컴포넌트가 존재한다. Java의 GC가 굉장히 대표적이고 유명하다는 생각이 들어서, Go의 GC에 대한 구체적인 내용을 설명하기 전에 JVM에서 사용하고 있는 GC의 구성을 조금 더 살펴보고 이를 Go와 비교해보려고 한다.
세대별 GC
Generational GC라고 불리는 GC 방법이다. 세대별이라는 말은 힙 영역을 세대별로 나눠 관리한다는 것을 의미한다. “세대”는 오래 살아남은 객체와 그렇지 않은 객체를 구분 짓는 것을 의미한다. 이 GC는 다음과 같은 대전제를 바탕으로 설계되었다.
- 대부분의 객체는 금방 접근 불가능 상태가 된다.
- 오래된 객체에서 새로운 객체를 참조하는 일은 드물게 발생한다.
위 대전제의 이름은 Weak Generational Hypothesis라고 한다. 이 가설을 이용해 Old 객체를 담는 영역과 Young 영역의 객체를 담는 영역으로 힙을 나눈다.
1 | <---- Tenured ----> |
- Young 영역: 새롭게 생성된 객체가 위치한다. 가설대로 많은 객체가 이곳에서 새로 만들어졌다가 사라진다. 이곳에서 발생하는 GC는 Minor GC라고 불린다.
- Old 영역: Young 영역에서 살아남은 객체가 여기 복사된다. Young 영역에 비해 크기가 크고, GC는 덜 자주 발생한다. 이곳에서 발생하는 GC는 Major GC 또는 Full GC라고 한다.
이 방법을 통해 일반적인 상황에서는 Minor GC로 간단하게 GC를 수행하게 된다. 큰 힙 영역을 다 확인할 필요 없이 일부만 확인할 수 있으므로 GC 속도가 빠르다.
💡 따라서 넓은 범위를 확인해야하는 Full GC가 자주 발생하는 상황은 문제가 있는 상황일 수 있다.
만약 2번 전제 상황이 발생하였을 때 GC가 어떻게 Old 영역이 참조하고 있는 Young 영역의 객체를 할당 해제하지 않을 수 있을까? 이를 위해 Old 영역에서 Young 영역의 객체를 참조하고 있는지 기록하는 Card Table을 사용한다. 이 테이블은 512 바이트의 청크로, Old 영역을 모두 확인하지 않고도 이 부분을 확인함으로써 Young 영역의 객체가 지워지는 것을 방지할 수 있다.
Compaction
힙 영역에 메모리를 할당하고 해제하는 과정이 반복되면 단편화 문제가 발생할 수 있다. 짧게 단편화에 대해 설명하자면, 전체적인 메모리 양은 요청된 메모리를 할당하기에 충분한 양인데, 연속되지 않아서 할당할 수가 없는 상황을 외부 단편화라고 부른다. 메모리가 비효율적으로 사용되고 있는 상황이고, 이런 파편화된 메모리 상태에서는 메모리 할당을 위해 메모리 공간을 찾는 시간도 늘어난다.
💡 Mark-Compact 방식을 쉽게 찾아볼 수 있었는데, 위에서 간단히 설명한 Mark & Sweep 방식에서 컴팩팅을 추가한 방식이다. 마킹 페이즈 이후 컴팩팅 페이즈가 존재해서 데이터들을 압축하고 이동한 오브젝트의 포인터를 업데이트 하는 과정을 거치게 된다.
Go의 GC
이제 Go에서 어떻게 GC를 구성하고 있는지 확인해보자. Go의 코드 주석으로 설명된 바에 따르면 Go는 비세대별, 비압축, Concurrent Tri-color Mark & Sweep이라고 한다.
- 비세대별: 힙 영역을 세대별로 관리하지 않는다.
- 비압축: 힙 영역의 Compaction을 수행하지 않는다.
- Concurrent Tri-color Mark & Sweep: 마킹과 해제 과정이 STW 없이 애플리케이션과 동시에 동작하고, 삼색 마킹 알고리즘으로 구현되어 있다.
Collector
Go GC는 세 개의 페이즈를 수행한다. 이 페이즈들 중 두 개는 STW를 유발하고, 다른 한 페이즈는 애플리케이션의 CPU 처리량을 느리게 만든다. 세 개의 페이즈는 다음과 같다.
- Mark 준비 - STW
- Marking - Concurrent
- Mark 종료 - STW
Mark 준비 - STW
GC가 시작되면서 가장 먼저 해야 할 일은 Write Barrier가 동작하도록(Enabled) 만드는 것이다. Go에서 Write Barrier는 동시적인 GC 마킹 과정에서도 힙 영역의 데이터 정합성을 유지해주는 장치이다. 위에서 살짝 써놨는데, 마킹 단계는 애플리케이션 고루틴과 GC 고루틴이 동시에 동작한다. 마킹을 하던 도중 애플리케이션 고루틴에서 힙 영역에 대한 변경 작업을 하게 되면 GC도 이를 인지하고 적절한 조치를 취해야 한다. 이것을 가능하게 해주는 것이 Write Barrier이다. 구체적으로 어떻게 해주는지는 이후 설명한다.
💡 Write Barrier라는 용어나 컴포넌트가 Go GC의 특수한 개념은 아니다. 동시적인 힙 영역에 대한 접근을 하기에 앞서 필요한 전처리 작업을 해주는 장치 정도로 사용이 되는 것 같은데, Java에서는 Old 영역에서 Young 영역을 참조할 때 Card Table에 기록하는 역할을 Write Barrier가 한다.
Write Barrier가 시작되려면 모든 애플리케이션의 고루틴들이 멈춰야 한다. 일반적으로 이 동작은 아주 빨라서 STW가 거의 발생하지 않는 것처럼 보인다.
Marking - Concurrent
Write Barrier가 켜지고 나면 마킹이 시작된다. GC가 이 단계에서 처음 하는 일은 25% 정도의 CPU 처리량을 가져오는 것이다. 예를 들어 4개의 P가 있으면 그중 하나는 GC를 수행하기 위해 점유(dedicated)된다.
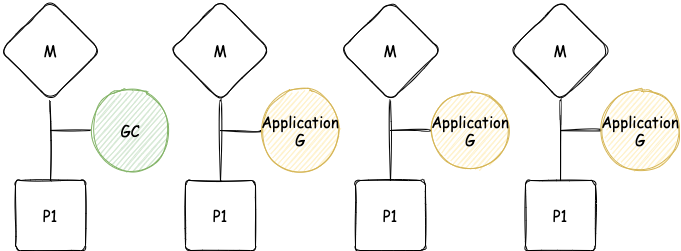
💡 위 이미지는 Go의 고루틴 스케줄링에 대해 알고 있으면 이해가 편한데, 만약 모른다면 사용 중인 스레드 중 하나가 점유된 이미지라고 이해하자. 그러나 엄밀히 말하면 틀린 소리기 때문에 시간이 된다면 Go GMP 구조에 대해 알아보자.
그다음 진짜 마킹을 하게 된다. 일단 현재 존재하는 모든 애플리케이션 고루틴 스택을 확인하면서 힙을 참조하고 있는 포인터를 확인한다. 스택을 스캔하는 과정은 해당 고루틴을 멈추게 한다. 하지만 그 이후 힙 안에서 오브젝트들을 따라가는 과정은 애플리케이션 고루틴과 동시에 동작한다. 다만 25%가량의 CPU 처리량을 사용하지 못하기 때문에 그만큼의 성능 저하가 발생한다.
만약 할당 속도가 너무 빨라서 고루틴이 사용 중인 힙 메모리 한계에 도달 전에 마킹 작업이 완료되지 못한다면 어떻게 될까? 할당이 지속되어 해당 오브젝트를 마킹 하느라 마킹 작업이 끝나지 않는다면? 이 상황이면 고루틴의 할당 속도를 낮출 필요가 있다.
GC가 힙 할당 속도를 제어해야 하는 상황이 되면 애플리케이션 고루틴 중에서 마킹 작업을 도와줄 어시스트 고루틴을 선정한다. 이를 Mark Assist라고 부른다. 애플리케이션 고루틴이 Mark Assist 역할을 하는 시간은 힙 영역에 추가되는 데이터 양에 비례한다. Mark Assist가 선정되면 그만큼 애플리케이션의 할당 속도는 줄고, 마킹 작업 속도가 빨라지는 효과가 있다. 그러나 애플리케이션 로직을 수행하는 비율이 더 줄어드는 것이기 때문에 속도 저하의 원인이 되기도 한다.
Tri-color Mark & Sweep에 대해 자세히 알아보자. 아래 이미지가 알고리즘 방식이다.
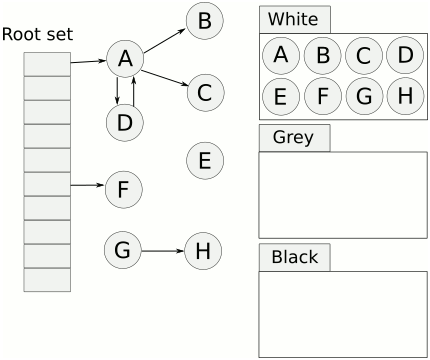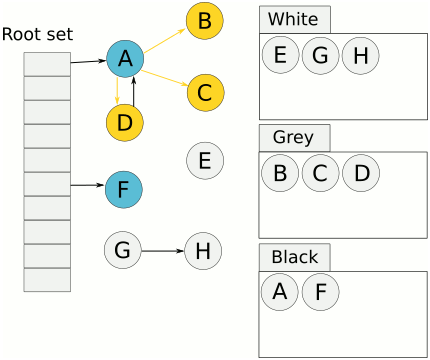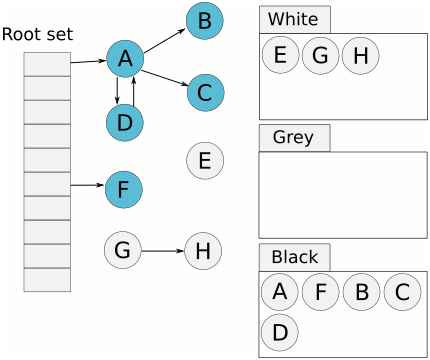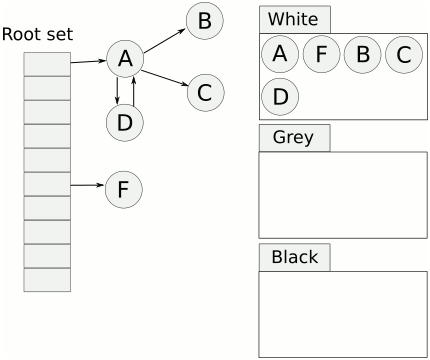
이미지 출처: 링크
- 먼저 모든 오브젝트는 하얀색 집합에서 시작한다.
- 루트 오브젝트를 회색 마킹한다.
- 회색으로 마킹된 오브젝트를 순회하면서 참조하고 있는 오브젝트들을 회색으로 칠한다.
- 순회를 마친 회색 오브젝트는 검은색으로 마킹한다.
- 3, 4번 스탭을 회색 오브젝트가 없어질 때까지 반복한다.
- 여전히 흰색 집합에 있는 오브젝트를 할당 해제한다.
위 과정은 STW 상태가 아니기 때문에 동시에 오브젝트 변경이 지속해서 발생한다. 위에서 언급한 것처럼 GC가 동작하는 도중에 애플리케이션 고루틴이 힙에 변경을 가하면 Write Barrier가 적절한 조치를 취한다. 예를 들어서 GC 도중 스택에서 새롭게 할당하는 오브젝트는 바로 검은색으로 마킹한다.
이미 존재하는 오브젝트 트리 구조에서 변경점이 생기면 Write Barrier에서는 변경이 생기기 전 Original Pointer와 변경이 생긴 New Pointer를 기록하고 두 포인터 모두 마킹 처리를 한다.
Original Pointer에 마킹처리를 하는 이유는 포인터 값을 스택이나 레지스터에 복사해두는 경우, Write Barrier를 거치지 않기 때문이다. Write Barrier는 힙 영역을 대상으로 발생하는 변경 점에 대한 전처리 작업을 하는 것이기 때문에, 로컬 스택이나 레지스터에 복사가 발생했는지 알 수 없다.
1 | [go] b = obj |
위와 같은 상황처럼, 스택에 복사된 상태로 사용할 때, 스캔하면서 할당 해제되는 상황을 막아준다.
New Pointer 역시 마킹 처리하는 이유는 다른 고루틴에서 포인터의 위치를 바꿀 수 있기 때문이다.
1 | [go] a = ptr |
위 상황처럼 만약 Write Barrier가 없다면 이미 스캔을 진행한 오브젝트에 아직 스캔을 진행하지 않은 포인터가 붙고 기존의 포인터를 담던 변수에서 제거되면 해당 힙 오브젝트가 스캔 되지 않을 수 있다.
이런 이유로 Write Barrier가 Original Pointer, New Pointer 모두 마킹 작업을 수행하도록 만들어주고, 동시적인 상황에서도 안전하게 힙 마킹을 유지할 수 있다.
Mark 종료 - STW
마킹 작업이 끝나면 Write Barrier와 Mark Assist를 종료하고 다음 GC가 동작할 목표치를 계산하게 된다. 이 과정은 STW 없이 동작할 수 있는데, 구현 시 코드 복잡성이 과하게 증가하는 반면 그에 비해 얻는 이점이 너무 작아 STW 상태로 진행된다고 한다.
다음 GC 수행을 위한 목표치 계산 알고리즘을 Pacing Algorithm이라고 부른다. 알고리즘은 콜렉터가 실행 중인 애플리케이션의 힙 사이즈 정보와, 힙에 가해지는 강도(Stress)에 의해 정의된다. Go에서는 GC Percent 값을 Go 환경 변숫값으로 설정해 GC가 동작하는 속도를 조절할 수 있다. 이 환경 변수 이름은 GOGC인데, 기본값은 100이다. 이는 현재 정리된 이후 힙 메모리보다 100% 커지면 다시 GC가 동작한다는 것을 의미한다. 즉, 기본값으로는 대략 2배 사이즈가 될 때마다 GC가 동작한다.
Sweep 과정?
어떤 글에서는 Sweep 페이즈에 대해 따로 페이즈로 나눠서 설명하기도 하는데, 이는 GC 사이클과 조금 독립적으로 동작하기 때문에 GC의 페이즈로 설명하지 않았다. Sweep은 애플리케이션과 함께 동시적으로 동작하는데, 애플리케이션에서 힙 영역에 할당을 요청했을 때 필요한 경우 삭제 처리된 오브젝트를 게으르게 할당 해제한다. 즉, 할당 시점에 Sweep이 발생하고 GC 수행 시간과는 무관하다. 그리고 다음 GC가 수행되기 전까지 아직 청소되지 않은 메모리 영역이 있다면, 모두 클린업 처리해주면서 다음 GC가 시작된다.
비압축 방식
압축을 통해 단편화 문제를 해결할 수 있는데, Go는 이 방법을 사용하고 있지 않다. 그렇다면 이 문제는 어떻게 해결하고 있을까? 이 문제는 현대 메모리 할당 방식에서 많이 해결해주고 있다고 한다. 전통적으로 프로세스 안에서 힙을 공유해 메모리를 할당해주는 방식은 멀티 스레드 프로그래밍에서는 그다지 적합한 방식이 아니다. 힙에 접근해 할당하는 과정에 Lock이 필요하기 때문이다. Go는 Google에서 만든 TCMalloc이라는 메모리 할당 방식을 활용하고 있다.
💡 “TCMalloc Like”라고 표현하던데, TCMalloc 방법을 사용했다고 이해해도 무방할 것 같다.
메모리 할당 방법 Overview
조금 개괄적으로 설명하자면, TCMalloc은 중앙 힙과 함께 스레드마다 로컬 스레드 캐시를 가지고 있고, 작은 할당은 로컬 스레드 캐시에서 해결한다. 필요에 따라 로컬 스레드 캐시에 새로운 메모리 영역을 할당해주거나, 중앙 힙에서 직접 큰 메모리 덩어리를 떼어 사용하기도 한다. 로컬 스레드 캐시로 인해 Lock이 필요 없는 할당이 빠르게 진행되기도 하고, 힙의 파편화된 영역을 최소화할 수 있는 원리로 작용하는 것 같다.
아래 구체적인 내용은 몰라도 남은 내용들을 이해하는 데 문제가 없다. 궁금한 사람들은 보기로 하자.
작은 메모리 할당
위에서 짧게 설명했지만, 작은 메모리를 할당하는 전략과 큰 메모리를 할당하는 전략이 다르다. 작은(32kb 이하) 할당을 할 때는 로컬 캐시인 mcache라고 불리는 메모리를 가져오려고 한다. 이 캐시는 32kb 짜리 청크 리스트인 mspan 리스트를 가지고 있다.
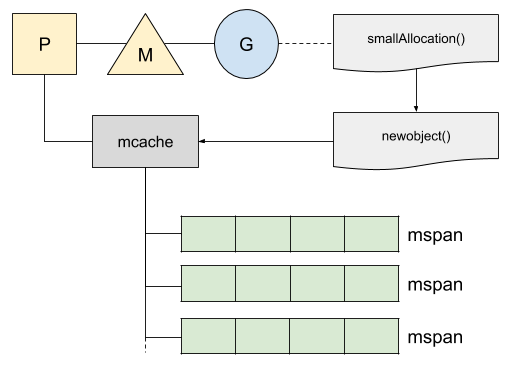
이미지 출처: 링크
고루틴 G를 처리하는 P에서 물고 있는 mspan 중 하나의 캐시를 사용해서 작은 범위의 할당을 한다. 이 과정은 힙 영역이 아니라서 Lock이 불필요하다. mspan은 32kb를 여러 사이즈로 나눈 여러 종류로 가지고 있다. 8bytes부터 32kb까지 클래스가 나눠진다.
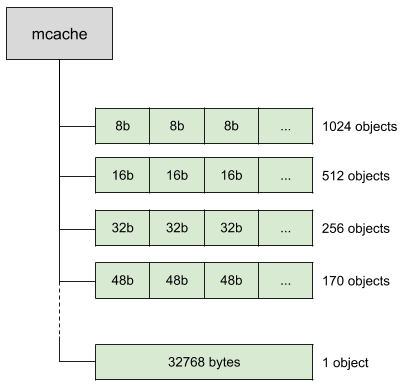
이미지 출처: 링크
그럼 만약 할당하려고 할 때 이 mspan 리스트에 충분한 슬롯이 없다면 어떻게 될까? Go는 중앙에 mcentral이라고 하는 메모리 공간을 관리한다. mcentral에는 두 가지 종류의 스판 리스트가 있다. 하나는 꽉 찬 스판과 다른 하나는 그렇지 않은 스판 리스트이다.
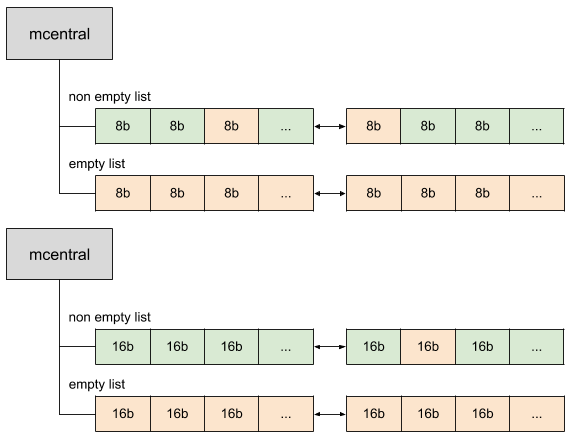
이미지 출처: 링크
mcentral에서는 스판 리스트가 양방향 연결 리스트로 되어있다. mcache에서 mspan이 꽉차게 되면 mcentral에서 빈 스판 리스트를 가져온다.

이미지 출처: 링크
만약 mcentral에서 제공할 수 있는 리스트가 없으면 힙에서 새로 할당받는다.
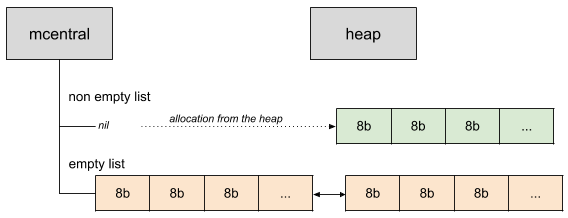
이미지 출처: 링크
힙이 메모리가 더 필요한 경우 OS로부터 메모리를 가져온다. 이때 새롭게 할당하는 영역은 arena라고 불리는 커다란 메모리 덩어리이다. 64bits 아키텍처일 때 64MB를 할당받고, 32bits인 경우 4MB를 할당받는다.
큰 메모리 할당
32kb보다 큰 메모리를 할당하게 되면 로컬 캐시를 사용하지 않는다. 할당되는 메모리 사이즈는 페이즈 사이즈로 올림 처리해 힙에 직접 할당한다.
대략적인 전체 흐름 이미지는 다음과 같다.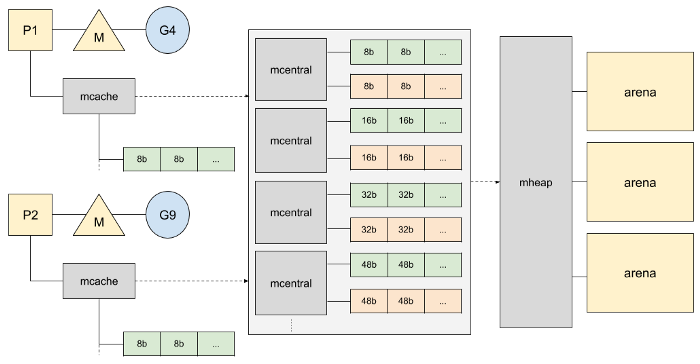
이미지 출처: 링크
비세대별 GC
힙 메모리를 스캔하는 범위를 좁히는 방법으로 비세대별 GC에 관해 설명했었다. Go에서는 이 부분이 도입되면 충분히 장점이 있을 것이라고 하지만, 현재는 도입된 상태가 아니라고 한다.
Go에서는 컴파일 최적화 과정인 Escape Analysis 단계에서 다른 언어와 다르게 실제 동적 할당하는 많은 부분을 스택에 할당하도록 한다. 세대별 알고리즘의 대전제인 “많은 오브젝트들은 수명이 짧다”에 해당하는 부분을 스택에 할당함으로써 GC의 대상이 아니게 만들어준다. 따라서 다른 언어에 비해 세대별 GC를 사용하는 것으로 생길 수 있는 장점이 비교적 작다.
일단 여기까지 내용이 Go의 GC가 어떻게 동작하는지, 그리고 왜 이런지에 관한 내용이다. 이후는 GC를 컨트롤하려는 케이스를 예시로 가져왔다. 위 내용을 모두 포함하고 있어서, 잘 이해했다면 아래 내용이 재밌다.
Case Study
GC Tuning 옵션에 관한 이야기
dotGo 2019 컨퍼런스에서 Go GC를 어떻게 쓸 수 있는지 설명한 얘기가 있다. Go는 GC 관련 설정을 할 수 있는 방법이 위에서 언급한 GOGC 환경 변숫값 하나뿐이다. 다음 두 가지 상황에서 GOGC가 어떻게 될지 설명하고 있다.
상황 1: 안정적인 큰 데이터셋이 있다면?
예를 들어서 20GB가 고정된 사이즈의 데이터라고 해보자.GOGC=100이라면 다음 GC는 40GB가 될 때 발생한다. 메모리 낭비가 굉장히 심한 상황인데GOGC=50으로 바꾸면 30GB에 동작하게 바뀐다.상황 2: 고정된 데이터 사이즈가 없는 애플리케이션 (작은 힙을 가지고 시작)
10MB의 힙 사이즈를 들고 시작했다고 가정해보자. GC는 20MB에 발생할 것이고, 정리되고 나서도 금방 다음 GC 사이클이 돌아온다. 이런 경우GOGC사이즈를 조금 여유있게 잡아주면 GC가 덜 발생한다.
위 컨퍼런스의 내용을 대충 요약하면 고정 메모리 소비량이 많으면 메모리 효율성을 위해 GOGC 값을 줄이고, 그 반대 상황에서는 GC 사이클을 줄이기 위해 GOGC 값을 크게 만들자는 내용이다. 굉장히 단순한 방법.
Twitch에서 Go 애플리케이션의 힙 사이즈를 수동으로 조절해 GC OPS를 줄인 이야기
Twitch는 Visage라는 프론트앤드가 바라보고 있는 API Gateway 앱을 가지고 있다. 이 앱은 EC2 + LoadBalancer 위에서 돌고있는 Go 애플리케이션이다. AWS 컴포넌트로 기본적인 스케일링 처리가 가능하지만, 애플리케이션 자체적으로 CPU 처리량이 급격히 떨어지는 상황이 있었다고 한다. Twitch에서는 이를 “리프레시 스톰”이라고 불렀다. 인기 있는 방송인의 인터넷 상태가 안 좋아지는 경우 시청자들이 다 같이 새로고침을 연타하는 경우 생기는 문제이기 때문이다. 이 경우에는 평소보다 약 20배가 넘는 트래픽을 유발한다고 한다.
트위치는 Go 프로파일링 옵션을 프로덕션에서도 켜놔서 쉽게 프로파일링 결과를 얻을 수 있었는데, 다음과 같은 보고를 얻었다고 한다.
- 안정적인 상태에서는 GC가 초당 8 - 10회 발생 (8 ~ 10 OPS)
- 30%의 CPU 사이클이 GC와 유관한 함수를 호출하기 위해 사용
- 리프래시 스톰 상황에서는 GC OPS 급증
- 평균적인 힙 사이즈는 450MiB
💡 프로파일링 옵션을 켜두는 것이 그렇게 오버헤드가 있지는 않다고 한다. Excution tracer는 오버헤드가 있을 수 있는데 시간당 몇 초 정도 수행할 정도로 수행 빈도가 별로 안된다고 한다.
GC OPS를 줄이고 STW 시간을 줄일 목적으로 밸러스트(바닥짐, Ballast)를 수동으로 만들어줬다. 앱이 시작할 때 아주 큰 메모리 사이즈를 힙에 할당해버리는 방법이었다.
1 | func main() { |
기본 GOGC를 유지한 상태였기 때문에, 밸러스트를 만듦으로써 약 10GB의 할당이 더 발생해야 GC가 동작했다. 결과적으로는 GC OPS가 99% 감소했다.
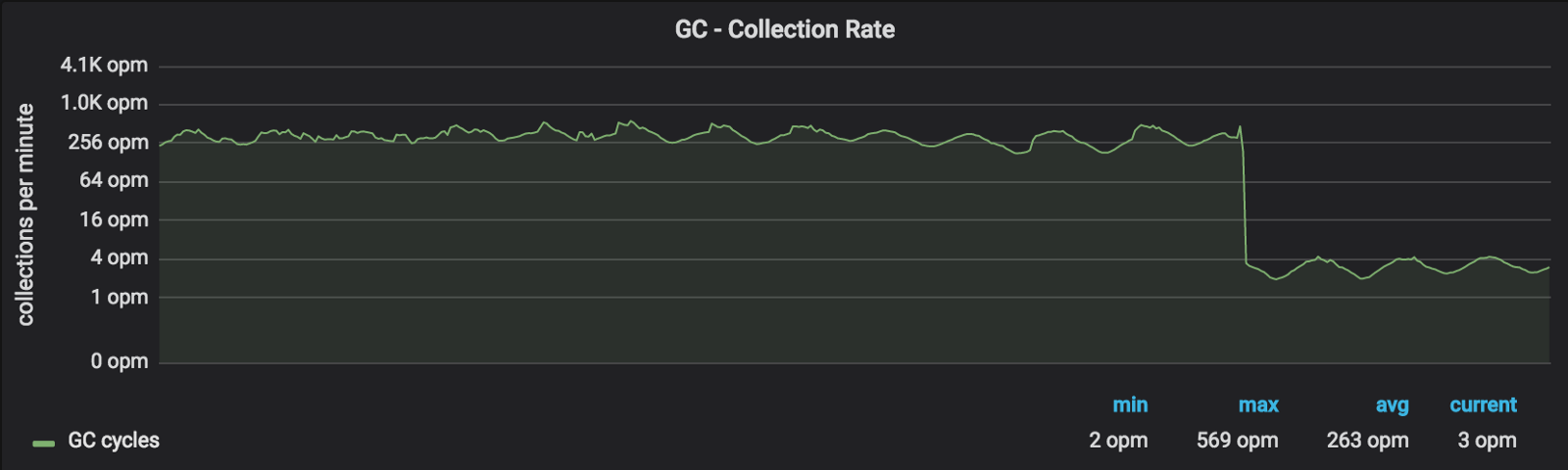
이미지 출처: 링크
CPU 활용도 30%가량 내려갔다.
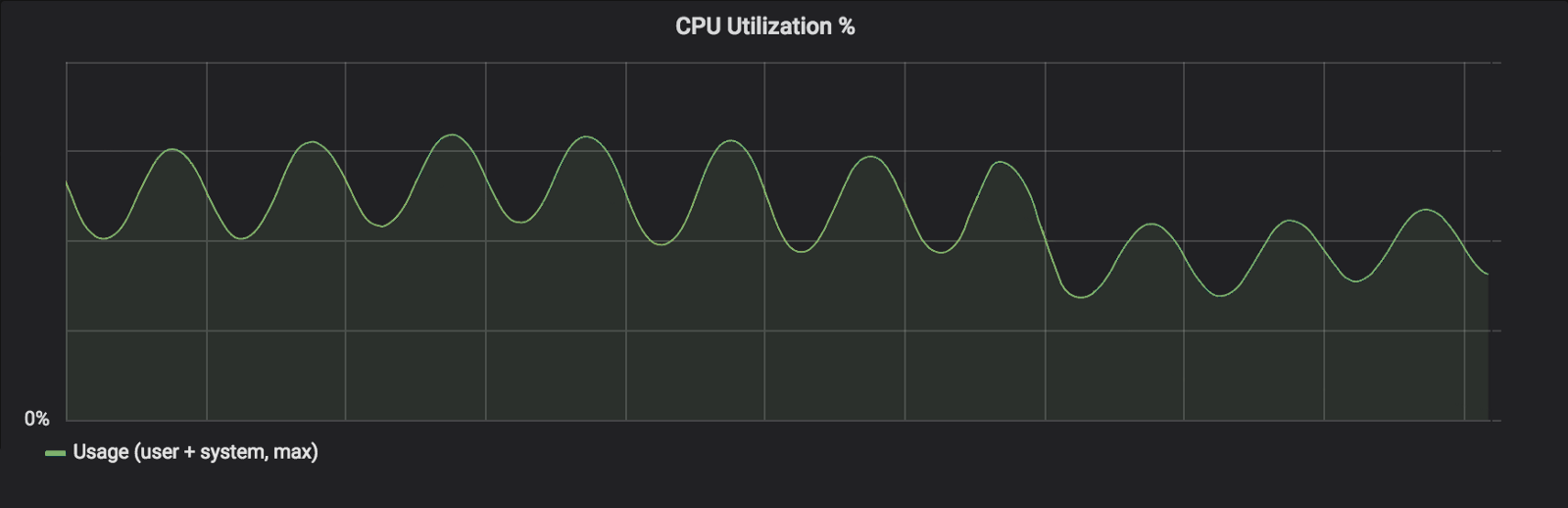
이미지 출처: 링크
GOGC를 설정하지 않고 직접 밸러스트를 만든 이유는 다음과 같다.
- GC 발생 비율은 관계가 없고, 총 메모리 사용량이 더 중요한 상황
- 밸러스트와 같은 효과를 발생시키려면 아주 큰
GOGC가 필요한데, 그렇게 하면 힙에 유지되는 메모리의 크기 변경에 아주 민감해짐 - 라이브 메모리와 변화하는 비율을 추론하는 것 보다, 전체 메모리를 추론하는 것이 훨씬 쉬움
그렇다면 소중한 10GiB 메모리가 그대로 소비되는 것은 아닐까? 실제 시스템 메모리는 OS에 의해 페이지 테이블을 통해 가상 주소가 지정되고 물리 메모리와 매핑된다. 위 밸러스트를 설정하는 코드가 실행되면 가상 메모리에 배열이 할당되고 실제 읽기 쓰기를 시도하면 페이지 폴트가 발생하면서 실제 메모리에 적재하는 과정이 발생한다. 따라서, 밸러스트가 물리 메모리를 차지하고 있지는 않다.
API 레이턴시 역시 많이 향상되었는데, Twitch는 처음에는 STW 자체가 줄어서라고 생각했지만, 실제로 STW가 줄어든 절대적인 시간 자체는 아주 짧았다. 실제로 성능 향상에 많은 영향을 줬던 것은 Mark Assist가 줄었기 때문이다. 위에서 언급했던 것처럼 Mark Assist가 동작하면 애플리케이션 입장에서는 CPU 처리량을 더 뺏기는 것이기 때문에 처리량이 줄어든다.
Reference
- https://deepu.tech/memory-management-in-programming/
- https://spin.atomicobject.com/2014/09/03/visualizing-garbage-collection-algorithms/
- https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/generations.html
- https://d2.naver.com/helloworld/1329
- https://en.wikipedia.org/wiki/Mark-compact_algorithm
- https://cs.opensource.google/go/go/+/refs/tags/go1.17.8:src/runtime/mgc.go
- https://www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
- https://programming.vip/docs/deep-understanding-of-go-garbage-recycling-mechanism.html
- http://goog-perftools.sourceforge.net/doc/tcmalloc.html
- https://medium.com/a-journey-with-go/go-memory-management-and-allocation-a7396d430f44
- https://groups.google.com/g/golang-nuts/c/KJiyv2mV2pU/m/wdBUH1mHCAAJ
- https://en.wikipedia.org/wiki/Escape_analysis
- https://youtu.be/uyifh6F_7WM
- https://blog.twitch.tv/en/2019/04/10/go-memory-ballast-how-i-learnt-to-stop-worrying-and-love-the-heap/
