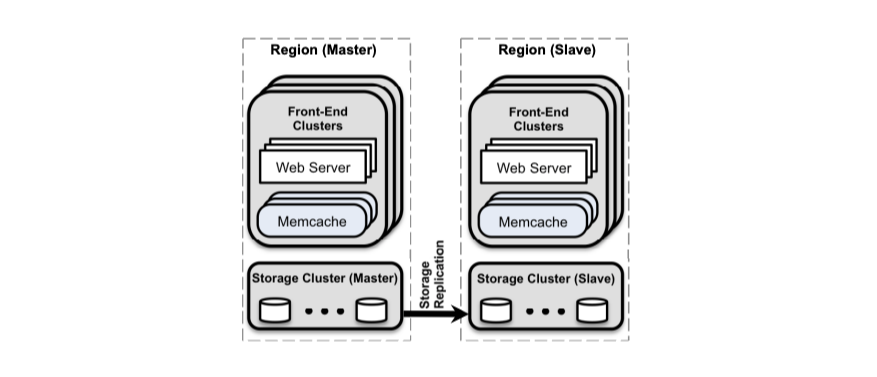
이 논문은 Planet Scale 서비스 중 하나인 Facebook(이하 Meta, 메타, 페이스북)이 어떻게 Memcache를 사용했는지에 대한 논문인데, 이 글은 이 논문 내용 중 “확장되는 스케일에서 어떻게 Data Consistency를 유지 했는가?”에 집중해 정리했다.
논문에서는
Memcache와Memcached용어를 철저히 분리한다. 전자는 분산 시스템을 구성하는 시스템 자체를 의미하고 후자는 실행되는 서버, 바이너리 자체를 의미한다.

