Scaling Memcache At Facebook
이 논문은 Planet Scale 서비스 중 하나인 Facebook(이하 Meta, 메타, 페이스북)이 어떻게 Memcache를 사용했는지에 대한 논문인데, 이 글은 이 논문 내용 중 “확장되는 스케일에서 어떻게 Data Consistency를 유지 했는가?”에 집중해 정리했다.
논문에서는
Memcache와Memcached용어를 철저히 분리한다. 전자는 분산 시스템을 구성하는 시스템 자체를 의미하고 후자는 실행되는 서버, 바이너리 자체를 의미한다.
Overview
메타에서는 캐시를 정말 대규모로 사용한다. 생각해 보면 페이스북은 캐시를 쓰기에 가장 적합한 유즈 케이스를 가지고 있다. 일단 논문에서 말하는 용례는 다음과 같다.
- Query Cache: 데이터베이스 읽기 부하를 줄이기 위해 사용한다. 특히
demand-filled look-aside캐시로 사용한다. - Generic Cache: 굉장히 일반적인 용례를 의미한다. 거의 나머지라고 보면 될 수준. 연산이 오래 걸리는 결과(ex. 머신 러닝 결과 등)라든지 어찌 됐든 무거운 무언가를 해야 하는 걸 담아두고 여러 서비스에서 꺼내서 쓰는 용도이다.
demand-filled look-aside캐시는 흔히 우리가 알고 있는 캐싱 방법이다. 읽어올 때 캐시를 확인 먼저하고 없으면 Origin 데이터 소스로부터 값을 가져오는 방식을 의미한다. 논문과 영상에서 짧게 나오는 내용 중에look-aside캐시를 만들기 위해서 Origin과 동기화를 위해 데이터 소스의 변경이 발생하면 캐시의 데이터를 수정하지 않고 삭제하는 방법을 선택했다고 한다. 보통 Cache Invalidation이 이렇게 동작하기 때문에 일반적인 것 같지만, 아무튼 삭제를 선택한 이유는 수정보다 멱등적이기 때문이라고 설명한다.
이 논문에서는 위 용례에 대해 (보통 Query Cache에 대한 내용인 듯) 배포 스케일에 따라 마주한 공학적 어려움을 설명해주고 있다. 이를 크게 세 단계로 나눠서 설명한다.
- 단일한 클러스터
- 여러 개의 Front-End(이하 FE, 프론트엔드) 클러스터
- 세계 단위로 여러 클러스터를 두는 상황
Single Cluster
이 수준에서는 지연을 줄이거나 Cache Miss로 인해 발생하는 부하를 줄이기 위해 노력하는 스케일이다. 이 장에서는 지연을 줄이기 위한 방법, 부하를 줄이기 위한 방법, 실패 처리에 대해 자세히 설명한다.
이 글에서 일관성 얘기를 위해 적합한 스테이지가 아니다. 만약 일관성 문제만 궁금하다면 멀티 클러스터 단위로 넘어가도 좋다.
지연 줄이기
우선 클러스터로 운영하고 있는 Memcache의 상황을 설명하자면, 수 백대의 Memcached 서버에 데이터가 Consistent Hashing으로 분산되어 있다. 또한 웹서버가 하나의 페이지를 만들기 위해 수많은 Memcached로부터 동시에 값을 읽어오게 된다. 예를 들어 인기 있는 페이지의 결과를 위해 평균적으로 521개의 독립적인 아이템을 Memcached에서 가져온다고 한다. 이러한 이유로 클라이언트는 짧은 시간에 엄청난 양의 데이터 응답을 받을 수 있는 상황이다. 이렇게 되면 다음과 같은 문제가 발생할 수 있다.
- 하나의
Memcached병목이 웹서버의 병목 지점이 될 수 있다. - 웹서버에
Incast Congestion이 발생할 수 있다. - 데이터 복제를 통해 단일 서버 병목을 완화할 수 있지만 데이터 비효율을 감수해야 한다.
Incast Congestion은 TCP 응답이 과도하게 몰려 TCP 윈도우를 압도하는 상황을 의미한다. 이 상황이 되면 패킷이 드랍되는 등 느려지는 원인이 될 수 있다.
이러한 문제를 메타에서는 Memcache 클라이언트를 개선해 해결했다.
Parallel Requests And Batching
Directed Acyclic Graph(DAG)를 그려 데이터 사이의 의존성을 확인한 후 웹서버가 동시에 Fetching할 수 있는 데이터를 최대로 뽑아낼 수 있게 만들었다. 이 구조로 동작하는 배치는 요청당 평균 24개의 키를 동시에 쿼리하게 되었다. 결과적으로 웹서버의 라운드 트립을 최소화하게 되었다.
Client-Server Communication
Memcached 서버는 각자와 커뮤니케이 하지 않는데, 시스템의 복잡성을 클라이언트에 주입했다. 이로써 Memcached 서버는 굉장히 단순하게 유지된다.
클라이언트는 GET 요청을 보낼 때 지연과 오버헤드를 줄이기 위해 UDP를 사용한다. 클라이언트는 시퀀스 넘버를 통해 UDP 요청에 문제가 있는지 확인할 수는 있지만 Recover 하지는 않는다. 이러한 경우는 그냥 Cache Miss와 동일하게 처리된다. 이러한 방법은 경험적으로는 굉장히 실용적이었다고 한다.
UDP 요청은 실제로 20%의 지연을 줄여주었다고 한다.
신뢰성을 위해 PUT & DELETE 요청은 여전히 TCP를 사용한다. 이를 처리하는 컴포넌트로 mcrouter가 있는데, 이는 Proxy로 동작하거나 라이브러리로 클라이언트에 삽입되기도 한다. 이 프록시가 클라이언트와 Memcached의 TCP 컨넥션을 줄여주는 역할을 함으로써 CPU, Memory, Network를 아꼈다.
Incast Congestion
클라이언트는 TCP Incast Congestion 문제를 보완하기 위해 자체적인 혼잡 제어 메커니즘을 가지고 있었다. 클라이언트는 Sliding Window(슬라이딩 윈도우) 방법을 사용해 요청 숫자를 제어했다. 슬라이딩 윈도우 방법은 말 그대로 TCP 혼잡 제어 방법처럼 천천히 증가하다가 문제가 생기면 줄어드는 구조이다. 윈도우 사이즈를 최적화하는 것도 중요한 문제였는데, 윈도우가 커지면 Incast Congestion을 막을 수 없어 성능 저하가 발생하고, 윈도우가 작아지면 요청들의 대기 시간이 길어졌다. 이것 역시 메타에서는 경험으로 적절한 수치를 찾은 것으로 보인다.
부하 줄이기
부하를 줄이기 위한 노력으로 세 가지를 소개하고 있다.
- Lease
- Memcache Pools
- Replication Within Pools
Lease
캐시를 사용하면서 생길 수 있는 문제로 오래된 데이터를 캐시에서 보관하는 Stale Set 문제와 특정 키가 굉장히 활발히 수정되고 읽히는 Thundering Herds 문제가 있는데, 메타는 위 문제들을 해결하기 위해 Lease 기술을 사용했다. Memcached는 클라이언트가 Cache Missing을 경험했을 때 데이터를 다시 채우기 위해 Lease 토큰을 발급해준다. 이 토큰은 64비트의 키 마다 유일한 값이다. 클라이언트는 캐시에 값을 저장할 때 Lease 토큰을 제공해야 한다. Memcached는 이를 확인하고 데이터가 저장되어야 하는지를 결정한다. 이때 “확인”(Verification) 과정은 말 그대로 “이 토큰이 특정 키에 대해 유효한가”를 보는 것이다. 예를 들어 Memcached가 요청을 받기 전에 해당 아이템을 삭제하라는 요청을 처리한 경우 토큰이 유효하지 않게 된 것이다.
이 동작 방식이 Load-Link/Store-Conditional이라고 하는 방식과 유사하게 동작하여 동시 쓰기로 인한 과거 데이터가 쓰이는 것을 막아준다. Load-Link/Store-Conditional 방법은 쉽게 말해 특정 값에 대한 쓰기 A가 수행되기 전에 다른 요청 B에 의해 처리되어버리면 A가 실패하도록 하는 로직이다.
Lease를 통해 Thundering Herds를 완화할 수도 있다. 각 Memcached 서버는 토큰 반환 속도를 조절할 수 있다. 기본으로 페이스북은 Memcached가 토큰을 10초마다 한 번 반환하도록 조정했다. 토큰 발급 후 10초 이내 값을 요구하는 경우 클라이언트에게 잠시 기다리라는 알람을 보낸다. 일반적으로 쓰기는 수 미리 초 안에 수행되기 때문에 10초 뒤의 클라이언트 요청은 데이터가 캐시에 존재하는 상황일 가능성이 높다. 하지만 이 동작은 선택적이고 만약 오래된 데이터를 어느 정도 감안하는 서비스라면 오래된 데이터일 수도 있지만 값을 리턴해준다.
Memcache Pools
위에서 언급한 Generic Cache로 사용할 때 여러 애플리케이션에 의해 사용되면 각 서비스가 다른 목적으로 접근하고 각 서비스에서 원하는 퀄리티 수준도 모두 다르다. 이는 사용 방법에서도 차이가 크게 생기기 때문에 Cache Hit을 줄이는 결과로 이어질 수가 있다. 이 차이를 해결하기 위해 Memcached 서버들을 다른 성격의 풀로 나눴다. 기본적으로 디폴트에 해당하는 풀이 있는데 이 풀을 WildCard라고 한다. 그리고 이 기본 풀에 있을 때 문제가 되는 키를 복수의 다른 풀에 분배하는 구조이다.
예를 들어서 자주 접근하지만 캐시 미스가 나도 큰 문제가 없는 키를 작은 풀에 할당하고, 자주 접근하고 캐시 미스가 나면 비싼 연산을 수행해야 하는 키를 조금 더 큰 풀에 담을 수 있다. 이로써 보다 적합한 키를 Eviction 처리할 수 있게 된다.
Replication Within Pools
어떤 풀들은 데이터 복제를 사용하고 있다. 다음과 같은 키는 복제를 사용한다.
- 앱에서 주기적으로 많은 키를 동시에 가져감
- 전체 데이터 셋 사이즈가 하나 혹은 두 개의
Memcached서버에 딱 맞음 - 요청 속도가 한 대의 서버에서 감당하기 어려운 수준
메타에서는 이런 경우 키를 나눠서 처리하는 방법 보다 복제해버리는 것을 선호한다. 예를 들어서 100개의 아이템이 있는데 다음과 같이 상황이 다른 것을 가정해 보자.
- 키를 공평하게 둘로 나눠서 가지고 있기
- 두 개의 서버에 100개를 모두 복제
요청이 1M/s 속도로 들어오고 있고 모든 키를 가져가야 하는 경우를 생각해 보자. 공평하게 둘로 나눈 상태라면 클라이언트는 아이템을 모두 얻기 위해 두 서버 모두에게 요청을 보내게 된다. 즉 두 서버가 모두 1M/s 부하를 받아야 하는 상황이다. 하지만 키가 두 Memcached 서버에 모두 동일하게 전체 셋이 복제되어 들어가 있다면 부하를 두 서버로 분산할 수 있게 된다. 단점이라고 하면 Invalidation을 두 번 해야 하는 것인데, 페이스북의 경우 요청을 분산하는 것이 Invalidation을 여러 번 처리하는 것보다 나은 선택이었다.
장애 복구
페이스북은 Memcache 장애를 두 가지 스케일의 장애로 나눠서 처리했다.
- 작은 장애: 몇 개의 서버가 영향을 받는 장애
- 큰 장애: 클러스터 내의 꽤 큰 퍼센트의 서버가 영향을 받는 장애
큰 장애는 그냥 다른 클러스터로 요청을 옮기는 형태로 장애를 복구한다. 작은 장애는 보통 자동 복구에 의존하는데 이런 시스템에 의한 복구는 시간이 걸린다. 그런데 이러면 장애가 전파될 수 있는 상황이 발생할 수 있으므로 이를 막기 위한 메커니즘으로 Gutter를 도입했다. Gutter는 장애를 복구하기 위해 사용하는 전용 머신이다. 이 전용 머신은 클러스터 내에 약 1%를 차지한다. 클라이언트가 서버로부터 응답이 없으면 서버가 죽었다고 판단하고 Gutter에게 요청을 보낸다. Gutter에서 캐시 미스가 발생하면 DB에서 값을 쿼리하고 데이터를 Gutter에 집어넣는다.
이는 살아남은 다른 캐시 서버에 Rehashing을 해서 값을 채우는 방식과는 차이가 있다. 살아남은 캐시 서버에 값을 넣는 것은 다른 서버로 장애가 전파될 위험이 있다. 죽은 서버는 내부에 있던 부하가 높은 키를 가지고 있을 수 있는데, 이 키가 다른 서버로 전달되어 다른 서버의 과부하로 이어질 수 있다. 그래서 아예 유휴 서버를 두고 위험을 제한하는 방법을 사용하는 것이다.
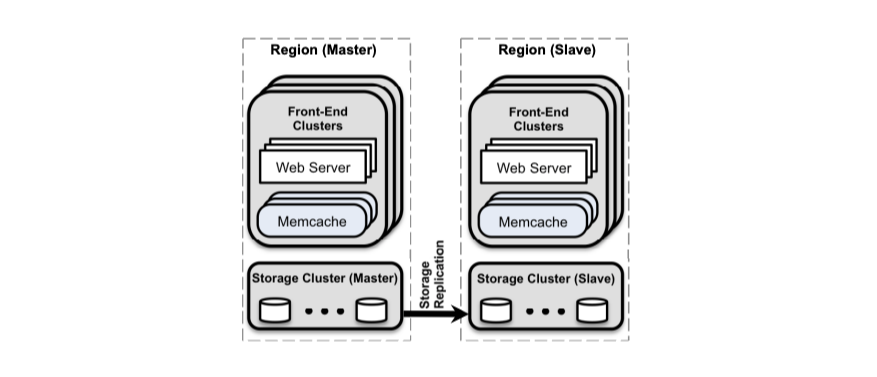
Multi-Clusters
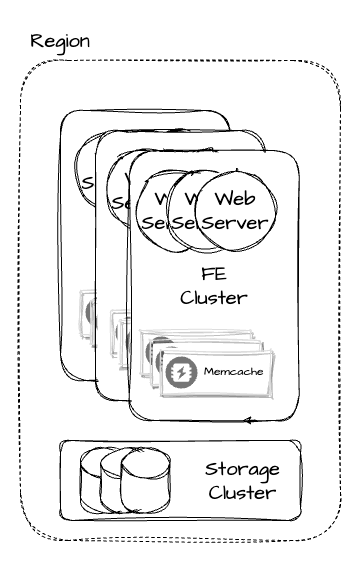
한 클러스터 안에서 Memcached 서버 수를 늘리는 것은 단순해 보이지만 온전한 해결책이 아니다. 장애 전파나 Incast Congestion을 피할 수 없게 될 수 있다. 따라서 Memcached를 복수의 클러스터로 만드는 방법을 선택했다. 이렇게 복수의 FE 클러스터와 하나의 스토리지 클러스터가 합쳐져서 Region을 구성한다.
논문에서 Web Server와
Memcached클러스터가 있는 것을 FE 클러스터라고 부른다.
Regional Invalidations
스토리지 클러스터가 FE의 Memcache와 데이터 정합성을 맞추기 위한 Invalidation 책임을 가지고 있다. 이를 위해 메타에서는 mcsqueal이라고 하는 Invalidation Daemon을 사용한다. 이 프로세스는 CDC 형태로 DB의 Delete 요청을 분석해 FE 클러스터에게 알려준다.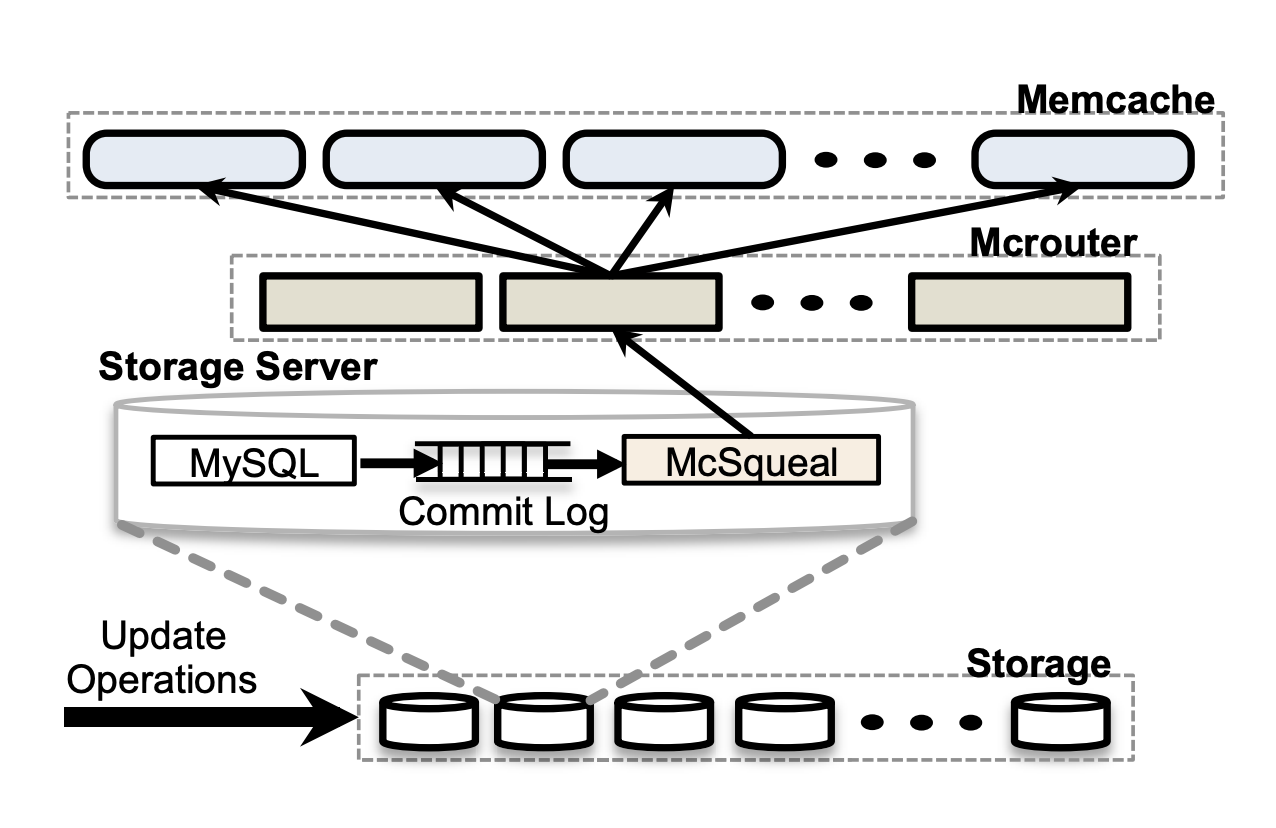
최적화를 위해 수정 요청을 보낸 웹서버도 자신의 클러스터 안에 있는 Memcache로 Invalidation 요청을 보낸다. 이로써 한 유저가 쓰기 후 읽기 작업을 할 때 보다 유의미한 결과를 전달해 줄 수 있게 된다.
Regional Pools
여러 클러스터 유저의 요청이 라우팅이 섞이면서 중복된 데이터들이 자동으로 여러 클러스터 안에 속하게 된다. 이는 클러스터 운영을 위한 캐시 중단을 만들었을 때도 다른 클러스터에 의해 Cache Hit가 줄어들지 않게 되는 등, 복제에 의한 장점이 생긴다. 하지만 문제는 메모리 비효율이 크다는 점이다.
이러한 메모리 비효율 문제를 해결하기 위해 Regional Pool를 적용했다. Regional Pool은 같은 Memcached 서버를 갖는 FE 클러스터를 의미한다.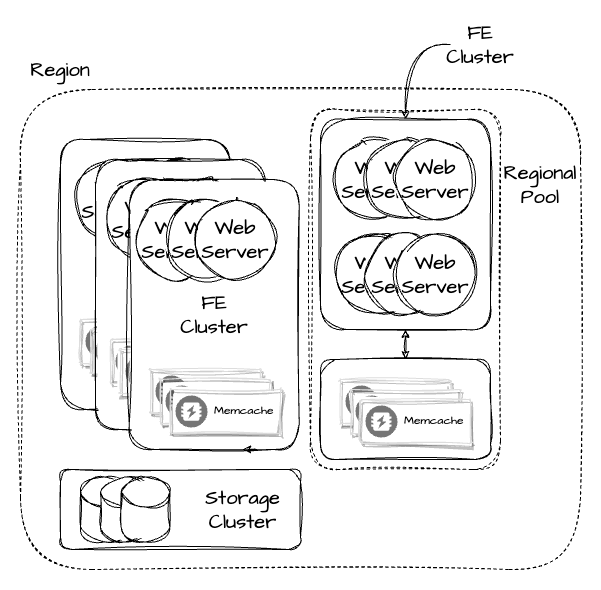
복제는 위에서 언급했던 것처럼 Failure Tolerance, 클러스터 안의 낮은 지연 등의 효과를 가지고 있지만 어떤 경우는 이렇게 하나의 캐시 데이터를 사용하는 경우가 나은 경우가 있다. 어떤 데이터와 웹서버를 Regional Pool에 옮겨야 하는지는 경험적인 수작업에 의해 진행된다. 요구되는 데이터 접근 속도, 데이터 사이즈, 특정 아이템에 접근하는 유니크한 유저의 숫자 등 여러 지표를 룰 베이스로 판단해 옮겨 넣는다.
마찬가지로 Regional Pool의
Memcache는 위에서 언급한 Gutter,mcqueal,mcrouter등의 시스템을 모두 사용한다.
Cold Cluster Warm up
Cold 클러스터를 Warm up 할 때는 Cache Miss 발생 시 스토리지 대신 Warm 클러스터에서 가져온다. 이런 방법으로 앞서 말한 FE 클러스터 간 데이터 복제 효과도 만들 수 있으며 스토리지를 사용한 것보다 빠르게 가져올 수 있다.
하지만 이 방법으로 인한 Race Condition이 발생할 수 있는데, 예를 들어 Cold 클러스터에서 삭제한 다음 곧바로 Cold 클러스터에서 해당 값을 읽는 상황을 생각해 보자. 방금 삭제되었기 때문에 없어야 맞는 값인데 이 Warm 클러스터와 데이터가 동기화되지 않은 상태로 Warm 클러스터에서 값을 가져온다면 Cold 클러스터의 이 값은 언제 끝날지 모르는 불일치가 발생한 상황이 된다.
이를 해결하기 위해 Memcached에서 키 삭제 요청을 처리한 다음 해당 키에 값을 추가하는 작업을 거부하는 기능을 사용했다. 이를 Hold-Off라고 하는데 Cold 클러스터는 2초의 Hold-Off 시간을 가지고 있다. 따라서 만약 어떤 키를 Warm 클러스터로부터 가져오려고 할 때 PUT 요청이 실패한다면 DB에 변경이 발생했다는 것을 알 수 있고, 이 경우는 DB에서 값을 가져오도록 되어있다.
이런 일관성 문제가 발생할 수 있지만 어찌 됐든 Warm up 방식이 그것보다 훨씬 큰 장점을 가져다준다. Cold 클러스터의 Cache Hit이 안정되면 Warm up을 종료하고 다른 클러스터처럼 동작하게 된다.
Multi-Regions
이전 챕터의 Region은 하나의 데이터 센터이다. 보통 페이스북 사이즈가 되면 데이터 센터를 대륙 혹은 지역 단위로 확장한다. 이를 통해 다음과 같은 장점을 얻을 수 있다.
- 클라이언트와 데이터 센터를 가까이 두어 지연을 줄인다.
- 특정 지역의 자연재해, 대규모 정전 등에 영향을 완화한다.
- 새로운 장소가 더 저렴한 전력, 경제적 장점 등을 줄 수 있다.
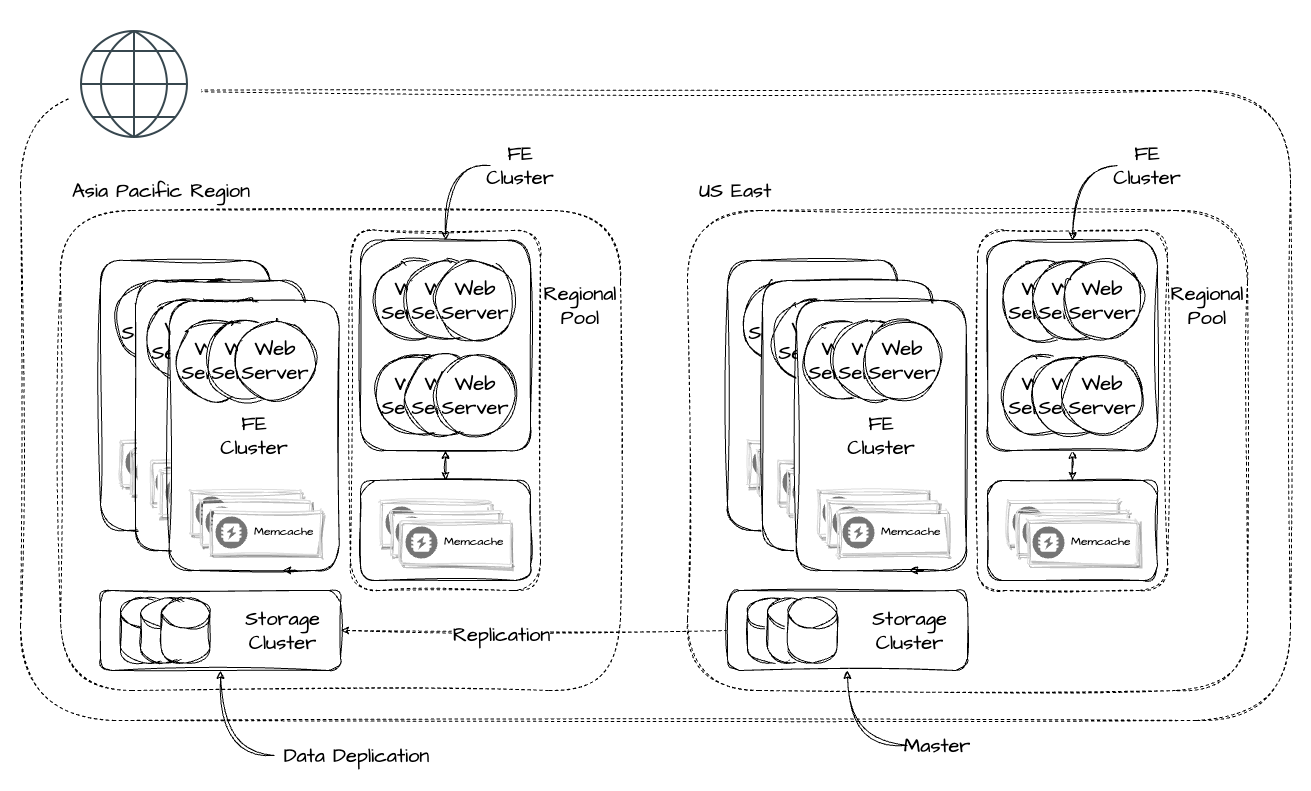
각 Region은 스토리지 클러스터와 몇 개의 FE 클러스터로 구성된다. 한 Region을 마스터 데이터베이스를 가진 Region으로 지정하고 다른 Region을 Read-Only Replica(이하 Replica)로 구성한다. 이 구성에서는 Memcache 혹은 스토리지 클러스터에 접근하는 경우 지연이 짧다.
여러 Region을 운영하게 되면 일단 스토리지와 Memcache의 데이터 일관성을 유지하기 어려워진다. 어려운 원인은 마스터 데이터베이스에서 데이터를 가져올 때 발생하는 지연(Lag) 현상이다. 보통 이런 시스템은 일관성과 성능을 어떻게 Trade-Off 할 것인지 광범위한 스펙트럼이 있고 메타 역시 이 스펙트럼의 어떤 한 지점을 고른 것이다. 이는 서비스의 특징 및 규모에 따라 경험적으로 선택되고 논문에서는 꽤 받아들일 수 있는 수준의 Trade-Off를 찾았다고 설명한다.
Master Region에서 쓰는 경우
Master Region은 이전에 설명한 한 Region에서 쓰기가 발생했을 때 mcsqueal이 동작하는 방법대로 동작한다. 하지만 이 Daemon 프로세스의 동작은 클러스터 안에서 한정된다. 다른 Region의 Memcache에 Invalidation을 전파하는 것은 동시성 이슈를 만들 수 있다. 예를 들어서 데이터가 수정되어 DB Replication이 발생해야 하는데, 이 데이터보다 Cache Invalidation이 먼저 도착하게 되고, 곧바로 클라이언트가 해당 키를 읽었다고 가정해 보자. 그러면 클라이언트는 해당 키에서 값을 못 찾고 Region 안에 있는 스토리지 클러스터에서 데이터를 찾게 된다. 그러면 오래된 데이터가 다시 캐시되고 유저는 오래된 데이터를 보게 된다.
Non-Master Region에서 쓰는 경우
복제 지연이 발생하고 있는 상황에서 Non-Master Region에서 데이터를 업데이트 한다고 가정해 보자. Region의 Memcache에 Invalidation을 했든 안 했든, Master 데이터베이스가 변경된 값을 Replica로 전달하지 않은 상태라면 업데이트를 요청한 유저가 오래된 데이터를 읽어오게 되는 상황이 생길 수 있다.
Name = "changhoi"라고 수정하고 새로고침 된 페이지에서 여전히"CHANGHOI"라고 보이는 상황을 의미한다.
따라서 Replica에서 데이터를 캐시에 채울 수 있는 순간은 복제 스트림을 따라잡고 난 다음이어야 한다. 만약 복제 스트림을 따라잡지 못한 상태라면 웹서버는 데이터를 Master Region 스토리지 클러스터에서 가져온다.
이 동작을 위해 Remote Marker를 도입했다. 한 서버가 K라는 키에 영향을 주는 업데이트를 한다면 다음과 같은 순서를 따른다.
- Region 안에 Remote Marker를
R(K)에 둔다. K와R(K)를 SQL 구문 안에서 Invalidation 될 수 있도록 포함시켜 마스터에 쓰기를 수행한다.- Region의
Memcache에서K를 삭제한다.
2번 단계가 구체적으로 이해가 잘 안되는데, SQL 구문이 Replica에 전파될 때
R(K)를 같이 없앨 수 있게 SQL 구문에 내장한다는 느낌이었다.
이렇게 동작하면 Cache Miss가 발생했을 때 K에 대한 마커가 남아있는 경우 Region의 Replica에서 아직 오래된 데이터를 가지고 있다는 뜻이 되므로 Master Region의 스토리지에서 데이터를 가져온다. 만약 마커가 없다면 Region 안에 있는 Replica에서 값을 가져온다.
Reference
Scaling Memcache At Facebook
https://changhoi.kim/posts/database/scaling-memcache-at-facebook/