DynamoDB 설계 방법: Single Table Design
NoSQL 종류 중 하나인 DyanamoDB는 일반적인 SQL 테이블과 다르게, query를 할 때 조건을 설정할 수 있는 대상이 Partition Key (이하 PK)와 Sort Key (이하 SK) 그리고 추가적으로는 Global Secondary Index (이하 GSI)와 Local Secondary Index(이하 LSI)로 구분되는 Secondary Index로 한정된다. 다른 속성 필드에 대해서는 쿼리 조건을 설정할 수 없다. 만약 다른 속성에 대해 결과를 보려면 scan을 사용해야 한다. scan은 테이블의 모든 데이터를 조회하기 때문에 성능면에서 좋지 않은 모습을 보여준다. 이러한 특성이 있어서, DynamoDB 테이블은 일반적으로 SQL 테이블을 만들듯 만들면 안 된다. 이 글은 AWS에서 공식적으로 추천하고 있는 Single Table 구조로 설계하는 방법에 대해서 다루고 있다.
DynamoDB와 RDBS 설계의 차이점
전통적으로 SQL 데이터베이스에서 테이블을 설계할 때, 스키마를 디자인하고, 데이터를 정규화 한 다음 사용하면서 필요한 쿼리를 작성하게 된다. AWS에서는 이 순서를 뒤집어 생각해야 한다고 설명한다.
다시 말해서 사용하게 될 쿼리들에 대해서 테이블을 만들기 전에 알고 있어야 한다는 뜻이다. 그래야 위에서 언급한 scan과 filter를 사용하는 것을 최소화 할 수 있게 된다. 또한, GSI는 테이블이 만들어진 이후에도 추가 또는 삭제가 가능하지만, LSI는 테이블이 만들어질 때 설정 해줘야 한다는 이유도 있다.
또한 AWS는 Single Table형태로 DynamoDB 테이블을 설계할 것을 추천한다. SQL 데이터베이스를 설계할 때는 보통 여러 테이블에 데이터를 나눠 담고, 관계에 따라 Relation을 설정한다. 데이터를 쿼리 할 때는 적절하게 Join하는 방식으로 데이터를 가져오게 된다. 이 방식은 개발자 입장에서 개발의 편리함을 주지만, 성능면에서 비용이 있는 방식이다. 하지만 DynamoDB는 SQL처럼 Join을 기본적으로 지원해주지 않는다. 즉, 일반적으로 SQL 테이블처럼 테이블을 나누기 시작하면, 복잡한 쿼리를 사용해야 할 때 여러 번의 쿼리를 사용해야 한다는 뜻이다. 이는 RDS보다 더 큰 비용을 감수해야 하는 샘이다.
배경 지식
간단하게 Primary Key와 Secondary Index에 대해 확인해보자.
글 전체에서 Primary Key는 줄이지 않고 사용했다. Partition Key는
PK로 줄여 사용했다. 마찬가지로 Secondary Index는 줄이지 않고 사용하고, Sort Key는SK로 줄여 표현했다.
Primary Key
Primary Key는 항목을 나타내는 고유 식별자가 되어야 하며, 두 아이템이 동일한 키를 가질 수는 없다. DynamoDB에서 Primary Key는 단일한 PK, 또는 PK와 SK로 구성될 수 있다.
Primary Key라는 조건때문에 단일 PK로 이루어진 경우는 아이템마다 다른 PK를 보장해야 하지만, SK와 함께 Primary Key를 구성한다면, 중복된 PK가 존재해도 된다. PK와 SK가 함께 사용된 Primary Key를 Composite primary key라고 하고, 이 경우에는 PK와 SK에 의해 항목이 구분될 수 있어야 한다.
DynamoDB는 PK의 해시 값을 계산해, 항목을 저장할 파티션을 결정한다. 동일한 PK를 가질 수 있고, 같은 값에 대해서는 같은 파티션에 SK의 오름차순으로 저장하게 된다.
Secondary Index
보조 인덱스라고 문서에 해석되어있지만, 글에서는 Secondary Index로 사용했다. 기본적으로 쿼리를 위해 PK와 SK를 사용하게 되지만, Secondary Index를 추가해 사용할 수 있게 된다. DynamoDB는 다음 두 가지 형태의 Secondary Index를 지원하고 있다.
Global Secondary Index (GSI) |
Local Secondary Index (LSI) |
|---|---|
PK와 SK로 구성되고, 기존 테이블과 달라도 된다. |
테이블과 같은 PK를 사용하지만, 다른 SK를 사용하게 할 수 있다. |
| 할당량 30개 | 할당량 5개 |
| 테이블 사용 중에 추가나 삭제 가능 | 테이블 만들 때만 생성이 가능하고 중간 삭제도 할 수 없음 |
Single Table Design
설계 방식
Single Table은 관계가 있는 테이블을 하나로 관리하는 것을 의미한다. 이 방법은 관계가 있는 테이블을 pre-join 하는 방법으로써 SQL 테이블 설계 할 때처럼 DynamoDB를 설계하면 나타날 수 있는 문제를 해결한 것으로 볼 수 있다. Single Table을 설계하는 과정은 다음과 같다.
- SQL 설계 하듯, 일반적인 ERD를 설계한다.
- 데이터 접근 패턴을 정의한다.
- Primary Key와 Secondary Indexes을 디자인 한다.
위 순서에서, 3 번의 경우, PK와 SK를 합쳐서 Primary Key를 구성하게 되는데, 이때 여러 테이블이 pre-join 되어있다고 봐야 하기 때문에, PK와 SK를 디테일한 이름을 가진 필드로 두지 말고 아주 일반적인 이름을 사용할 것을 권장한다. 그렇게 설계한 뒤 PK와 SK를 통해 어떤 Entity에 접근 하고 있는 건지 구분 할 수 있게 해야 한다. 자세한 예시를 확인해보자
예시
2019 AWS re:invent에서 들어준 예시를 확인해보자. E-commerce 서비스를 위해 User와 Order테이블을 설계하는 예시이다.
실제로는 아래 예시에서 조금 더 나아가 Filtering Pattern에 대해서도 다룬다. 정말 정리 해두고 싶은 내용이지만, 글 분량이 너무 길어지고 적당하게 잘 정리할 수 있을지 모르겠어서 생략했다.
먼저 ERD 정의를 해줘야 한다. ERD를 정의는 다음과 같이 했다.
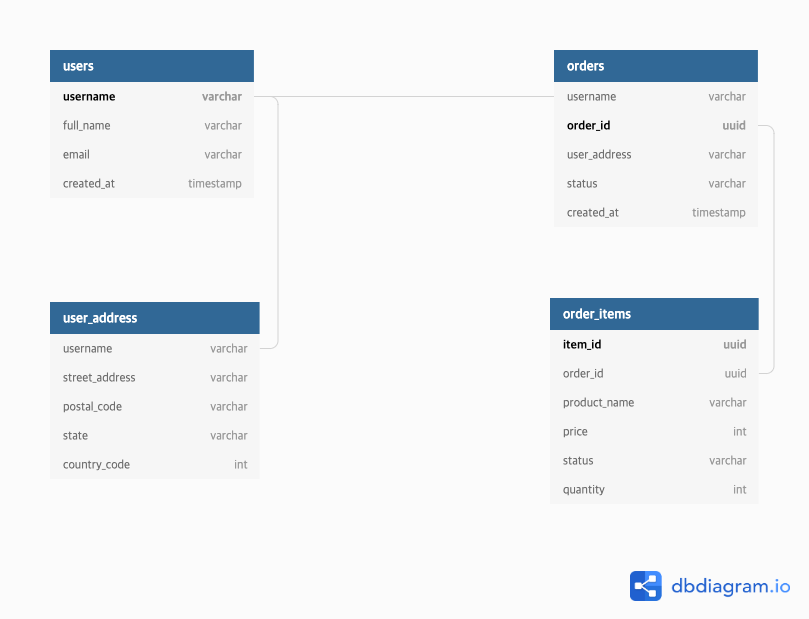
다음은 데이터 접근을 어떻게 할지 미리 정의해야 한다. 예시에서 애플리케이션에서 다음과 같은 접근 패턴을 갖고 있다고 가정해보자.
- User Profile 가져오기
- User에 대한 Order 리스트 가져오기
- 단일한 Order와 그에 대한 Order Items를 가져오기
Primary Key와 Secondary Indexes를 설계할 차례이다. 위에서 말한 것 처럼 일반적인 이름으로
PK와SK를 만들고, 두 값으로 어떤 Entity에 접근하는지 구분할 수 있게 설계한다.
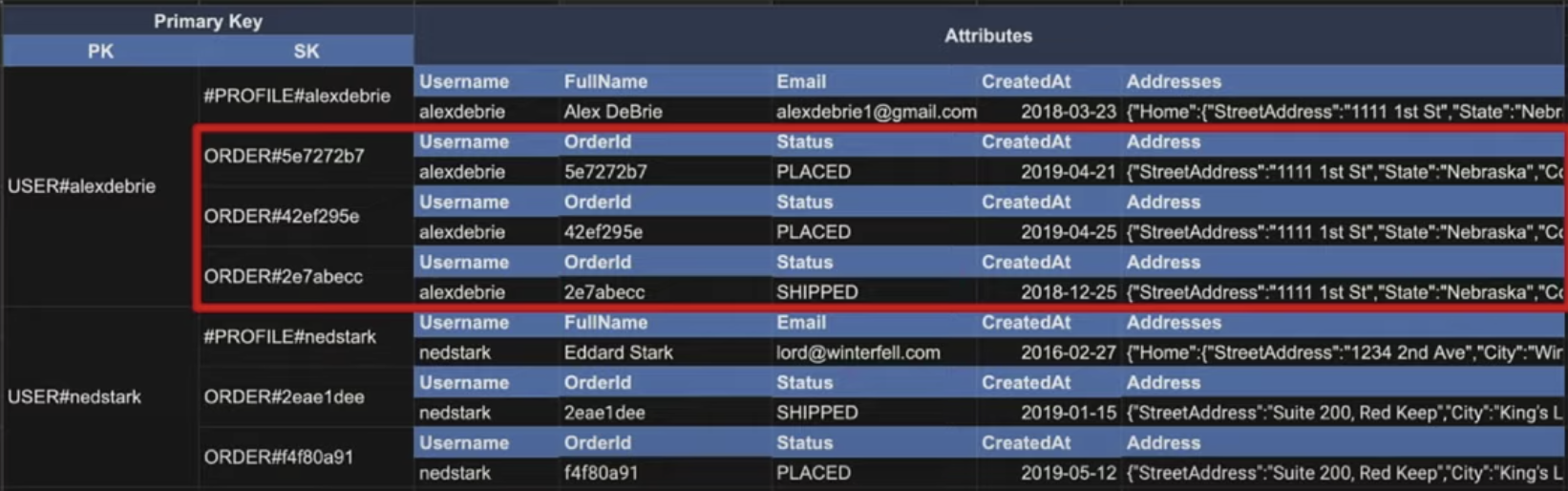
데이터 예시
위 데이터는 users, user_address, orders 관계를 일부 반영한 모습이다. ERD와 설계한 접근 패턴을 반영했는지 확인해보자.
Primary Key는 PK와 SK로 구성되고, PK는 USER#username, SK는 #PROFILE#username 또는 ORDER#orderId 형태로 구성되고 있다. 이렇게 패턴을 정의해서 어떤 Entity에 접근하는 건지 구분 할 수 있게 만들면 된다.
user_address는 1:N 관계지만, user_address 자체를 PK또는 SK로 쿼리 해야하는 경우는 없다. (예를 들어서, 주소를 기반으로 유저를 검색하거나, 주소에 따라 유저들을 가져오는 쿼리는 필요가 없다.) 따라서 비정규화 + Document 타입의 Address라는 이름으로 필드에 추가된 모습이다. 다만 Address는 Orders의 필드로서의 역할도 한다. 두 경우는 다른 모습을 가질 수 있다.
orders와 users도 마찬가지로 1:N 관계이다. 다만 위와 다르게 Order에 따른 쿼리가 필요하다. 따라서, PK와 SK로 User에 따라 Order 리스트를 쿼리할 수 있어야 한다. 예를 들면 아래와 같이 쿼리할 수 있게 된다.
1 | PK = USER#alexdebrie AND BEGIN_WITH(SK, 'ORDER#') |
위 쿼리로 유저에 대한 Order 리스트를 가져올 수 있게 된다.
지금까지 설계된 테이블은 아래 모습을 갖췄다. 하지만 아직 orders와 order_items 관계는 설계되기 전 모습이다.

Order에 따라서 Item을 가져오지 못하므로 남은 부분들을 고려해 테이블을 설계해보자. orders와 order_items의 관계를 살펴보면, 마찬가지로 1:N 관계이다. 그리고 단일한 Item 조회를 해야 한다는 점을 반영해 아래와 같이 PK 패턴을 정의해 넣을 수 있다.
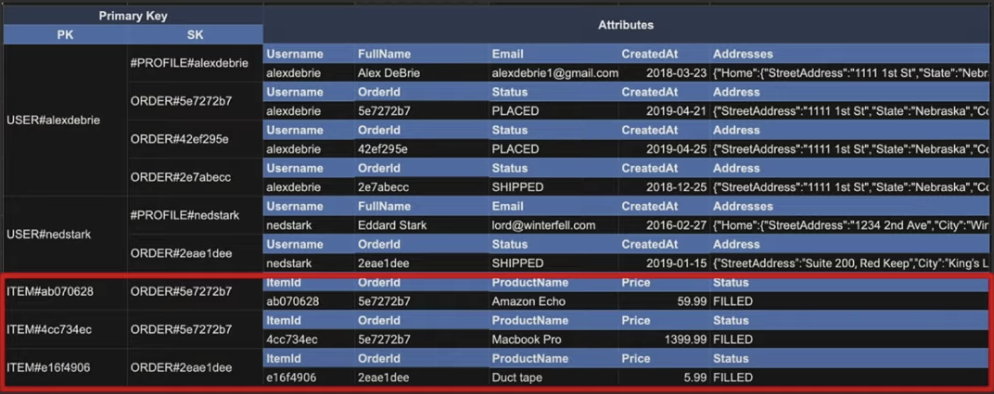
결과적으로 Entity를 아래 이미지 처럼 설계하게 되었는데, 이때 관계에 따라 동일한 패턴을 PK또는 SK로 쓰게 하는 것이 중요한 핵심이고, 이 방식으로 설계 해야 Join 하는 것과 같은 효과를 가질 수 있다.

지금까지 진행된 설계의 문제는 Order를 기준으로 데이터를 가져오는게 불가능하다는 점이다. PK에서 Order를 쿼리할 수 없기 때문인데, 이를 해결하기 위해서 Secondary Index를 설정해보자.
이번 예시에서는 Inverted Index라고 불리는 전략을 소개한다. 이 전략은 말 그대로 PK와 SK를 뒤집은 Primary Key를 GSI로 만드는 것이다.
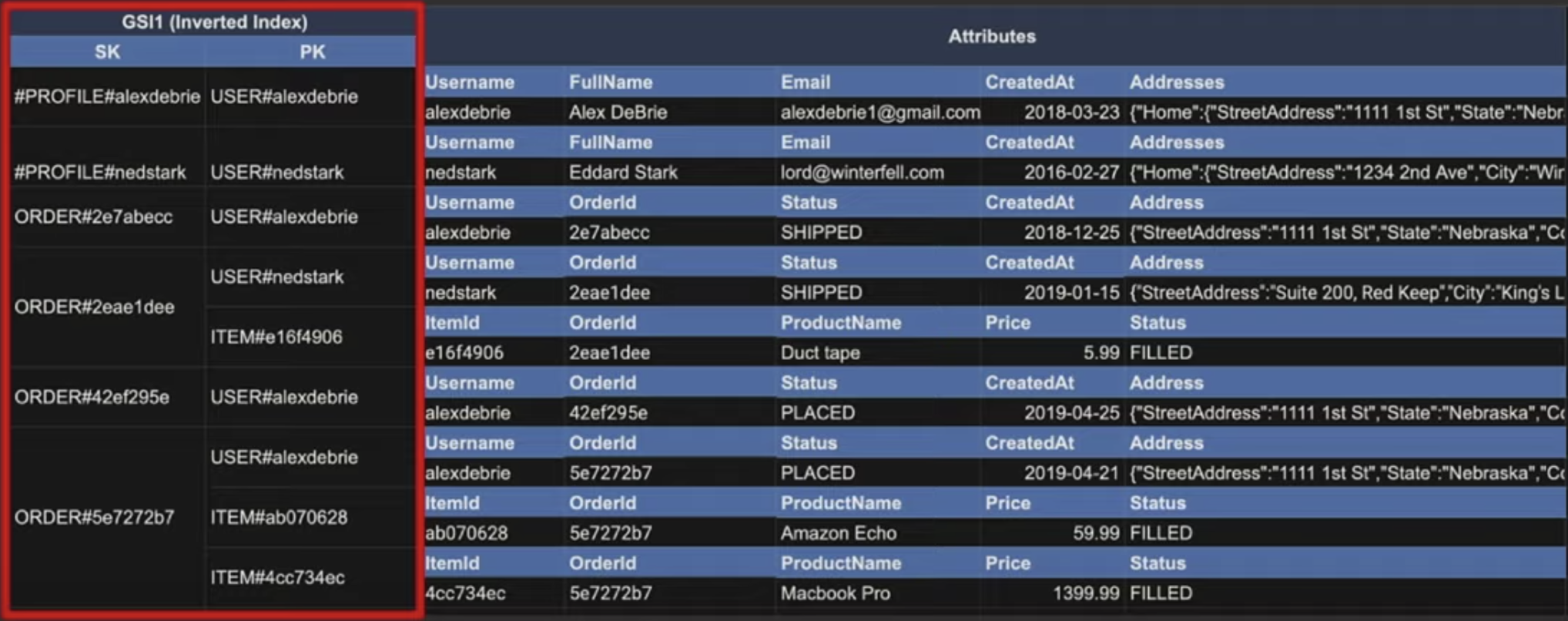
위와 같은 GSI를 만들면, Order를 쿼리 했을 때, 두 가지 타입의 Entity에 바로 접근이 가능해지는데, Order에 따른 Item 리스트와, Order의 User를 가져오게 된다. 이렇게 데이터를 쿼리하면 orders에 users와 order_items를 조인한 것과 같은 결과를 갖게 된다.
위 예시를 정리해 보자면 ERD에서 1:N 관계로 설계 했을 때, DynamoDB의 테이블을 설계하는 패턴들에 대해서 다루고 있다.
- Denormalizing + Attributes화 하기 (
user_address와users) - Primary Key로 구성해서 쿼리 (
users와orders) - Secondary Index를 구성해서 쿼리 (
orders와order_items)
미리 두 번째 단계에서 설계했던 접근 패턴에 대해서 이제 다음과 같은 쿼리 형태로 접근할 수 있게 됐다. (나타낸 코드는 실제 코드가 아닌 의사코드이다.)
1 | - User Profile 가져오기 |
Single Table Design의 한계
Single Table Design은 DynamoDB에 아주 적합한 설계 방식이지만, 몇 가지 한계점이 있다.
우선 가장 큰 문제는 필요한 쿼리를 미리 알고 있어야 한다는 점이고, 새로운 접근 방식을 정의해야 하는 경우에 어려움이 따를 수 있다는 점이다.
그리고 설계에 있어서 유연성이 떨어지는 점도 있다. 특히 LSI는 한 번 만들어지고 나면 수정이 되지 않기 때문에 여러 테이블을 모아놓은 하나의 테이블의 설계가 적합하지 않는 경우에 수정이 어렵다. 또한 이 방법 자체에 대한 이해와 적용이 까다롭다는 점도 한계라고 볼 수 있을 것 같다.
Reference
- The What, Why, and When of Single-Table Design with DynamoDB
- Advanced Design Patterns for Amazon DynamoDB
- Single Table - Week 4 | Coursera
- AWS re:Invent 2019: Data modeling with Amazon DynamoDB (CMY304) - YouTube
- AWS DynamoDB Docs: Core Components of Amazon DynamoDB
- AWS DynamoDB Docs: Partitions and Data Distribution
- AWS DynamoDB Docs: Improving Data Access with Secondary Indexes
DynamoDB 설계 방법: Single Table Design
https://changhoi.kim/posts/database/dynamodb-single-table-design/