RDB는 흔히 말하길 스케일링 (스케일 아웃) 하기 까다로운 데이터베이스라고들 한다. NoSQL이 등장하며 내세웠던 차별점 역시 이러한 부분(확장성)이 포함되어있다. 하지만 RDB가 스케일 아웃이 불가능하다는 건 절대 아니다. 많은 거대한 서비스들이 RDB를 사용하고 있고, 이 서비스들은 많은 방법으로 스케일 아웃을 구현하고 있다. 이 방법에 대해서 정리한 글이다.
자세히 보기
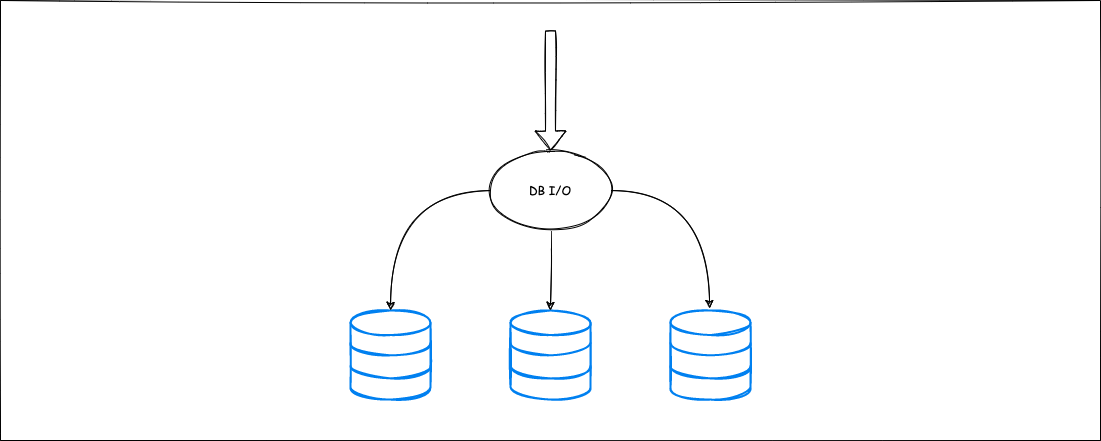
RDB는 흔히 말하길 스케일링 (스케일 아웃) 하기 까다로운 데이터베이스라고들 한다. NoSQL이 등장하며 내세웠던 차별점 역시 이러한 부분(확장성)이 포함되어있다. 하지만 RDB가 스케일 아웃이 불가능하다는 건 절대 아니다. 많은 거대한 서비스들이 RDB를 사용하고 있고, 이 서비스들은 많은 방법으로 스케일 아웃을 구현하고 있다. 이 방법에 대해서 정리한 글이다.
최근에 시험도 준비하고, 일도 바빠서 쉽게 글을 남기기 힘들었는데, 쓸 내용들은 차곡차곡 쌓아두긴 했었다. 우선 정리와 복습도 할 겸, 최근 서비스에서 사용하고 있는 MongoDB 모델링 하는 걸 공부한 내용을 정리했다. 이 내용은 공식 문서를 보고 번역하고 재배열한 내용이다.

DynamoDB 설계 방법: Single Table Design
NoSQL 종류 중 하나인 DyanamoDB는 일반적인 SQL 테이블과 다르게, query를 할 때 조건을 설정할 수 있는 대상이 Partition Key (이하 PK)와 Sort Key (이하 SK) 그리고 추가적으로는 Global Secondary Index (이하 GSI)와 Local Secondary Index(이하 LSI)로 구분되는 Secondary Index로 한정된다. 다른 속성 필드에 대해서는 쿼리 조건을 설정할 수 없다. 만약 다른 속성에 대해 결과를 보려면 scan을 사용해야 한다. scan은 테이블의 모든 데이터를 조회하기 때문에 성능면에서 좋지 않은 모습을 보여준다. 이러한 특성이 있어서, DynamoDB 테이블은 일반적으로 SQL 테이블을 만들듯 만들면 안 된다. 이 글은 AWS에서 공식적으로 추천하고 있는 Single Table 구조로 설계하는 방법에 대해서 다루고 있다.
Update your browser to view this website correctly.&npsb;Update my browser now