gRPC를 지탱하는 기술
gRPC는 쉽게 말해서 HTTP/2.0 위에서 동작하는 RPC이다. 국내에서도 당근마켓, 뱅크샐러드, 데브시스터즈 같은 조직들이 gRPC를 활용하기 시작하면서 이미 많이 알려진 커뮤니케이션 방법이 되었다. 이번에 gRPC를 사용하게 되면서 어떤 기술들로 구성되어 있고, 어떤 대안들과 비교했을 때 어떤 장점이 생길 수 있는지 공부했던 내용을 정리했다.
gRPC의 특징
유명한 오픈소스 기술들은 공식문서에 특징을 명확히 정리해서 보여준다. gRPC도 당연히 구글이 만든 잘된 프로젝트기 때문에 이러한 특징들이 간단명료하게 정리 되어있다.
gRPC is a modern open source high performance Remote Procedure Call (RPC) framework that can run in any environment. It can efficiently connect services in and across data centers with pluggable support for load balancing, tracing, health checking and authentication. It is also applicable in last mile of distributed computing to connect devices, mobile applications and browsers to backend services.
정리하자면 다음과 같은 특징이 있다.
- gRPC는 High Performance
- 여러 데이터 센터들 사이에 효율적인 연결
- 트레이싱, 헬스 체킹, 인증, 로드 밸런싱 포함
- 플랫폼 독립적으로 백엔드 서비스와 연결할 수 있음
조금 더 구체적인 설명으로는 Protocol Buffer를 사용해서 Binary Serialization(직렬화)를 했고, HTTP/2.0을 사용해서 Bi-Directional 스트리밍이 가능하다는 내용과, 기타 크로스 플랫폼, 스텁을 생성해줘서 간단하게 개발할 수 있다는 내용 등이 나온다.
이런 특징들은 쉽게 말해서 “우리 기술을 사용하면 이런 장점이 있어”를 설명한 내용이다. 전반적인 벤치마크를 가지고 이런 특징을 내세우고 있겠지만, gRPC 같은 경우 생각해보면 대안은 대충 두 가지 갈래로 나눠질 수 있다. 첫 번째는 REST API를 대체하는 것이고, 두 번째는 Binary 인코딩을 하는 다른 구현체, 예를 들어 Thrift 같은 것들이다.
사실 그런데 후자의 경우 보통 gRPC로 통일되고 있는 분위기이기도 하고, 보통 고민하고 있는 갈래가 보다 전통적인 방식의 HTTP/1.1 + JSON을 사용하는 REST API vs gRPC이기 때문에 이번 글 역시 REST API에 비해 어떤 장점을 설명할까에 집중해서 내부적인 부분들을 파헤쳐보려고 한다.
일단 설명 전이지만, REST API는 gRPC와 비교 범주가 조금 다르긴 하다고 생각한다. gRPC는 아주 구체적인 구현체이고 REST API는 이론에 가까운 단어이기 때문이다. 그런데 일단 전통적인 방식과 비교하자는 의미이다. REST API가 JSON을 사용해야 한다는 것도 아니고 HTTP/1.1을 써야만 한다는 것도 아니다. 그냥 일반적인 상황을 얘기하는 것이다. “HTTP/1.1 프로토콜 위에서 JSON 바디를 보내는 방법”을 줄여 간단히 REST API라고 작성한 것으로 이해하자.
위 장점 중 트레이싱, 헬스 체킹 등 에코 시스템 관련된 장점과 크로스 플랫폼이라는 특징은 REST API를 타겟으로 한 소리는 아니라고 볼 수 있다. 따라서 gRPC가 어떻게 REST API에 비해 High Performance, 효율적인 연결을 이룰 수 있는지 위주로 풀어보자.
CORE 1: HTTP/2.0
gRPC는 HTTP/2.0 위에서 동작하는 RPC라고 가장 처음 설명했다. gRPC는 HTTP/2.0 프로토콜을 구현하는 것으로 다음과 같은 이점을 가지게 된다.
- 컨넥션 수 감소
- Long-live Connection
- Bi-Directional Concept
HTTP/2.0의 기술적 목표
기존 HTTP/1.X에서는 다음 문제들이 있었다.
- Plain Text (ASCII) 프로토콜이기 때문에 Human-Readable 하므로 디버깅이 쉽지만, 아스키 코드 특성상 비슷한 다른 코드들이 여럿 존재한다. 예를 들어 다양한 White Space 종류들과 Termination을 의미하는 여러 코드, New Line을 의미하는 여러 코드 등 파싱 단계에서 생길 수 있는 문제가 있기도 하고 보안상 문제가 되기도 했다.
- Plain Text라는 사실은 곧 불필요한 공간을 많이 사용하고 있다는 것을 의미하고, 이는 네트워크 친화적이지 않다는 것을 의미한다.
- HOL(Head Of Line) Blocking 문제를 발생시킬 수 있다.
- Parallel Connection을 통해 큰 오브젝트를 전달받을 때 비효율성을 해결하려고 했으나, 결국 컨넥션을 많이 사용해야 한다는 것을 의미한다. 서버의 구현 레벨에서 일반적으로 Connection은 스레드를 의미한다. 스레드는 메모리 등 컴퓨팅 자원을 소모하게 된다.
위 문제들은 현재까지도 어느 정도 감안하며 사용하고 있을 정도로 크리티컬하다고 판단되지는 않는다. 그런데 구글 정도의 사이즈는 이런 문제를 해결했을 때 오는 효용 역시 엄청나기 때문인지, 새로운 프로토콜을 개발했다. 처음 만들어진 것은 SPDY인데, 역사 얘기를 하지는 않을 것이고 결국 발전해서 HTTP/2.0이 되었다. HTTP/2.0의 디자인과 기술적 목표는 다음 같다.
- 네트워크 리소스를 더 효율적으로 쓸 수 있고, 지연을 줄일 수 있어야 한다.
- 기존 HTTP/1.1을 대체하는 방식이 아니라 확장하는 방법이어야 한다.
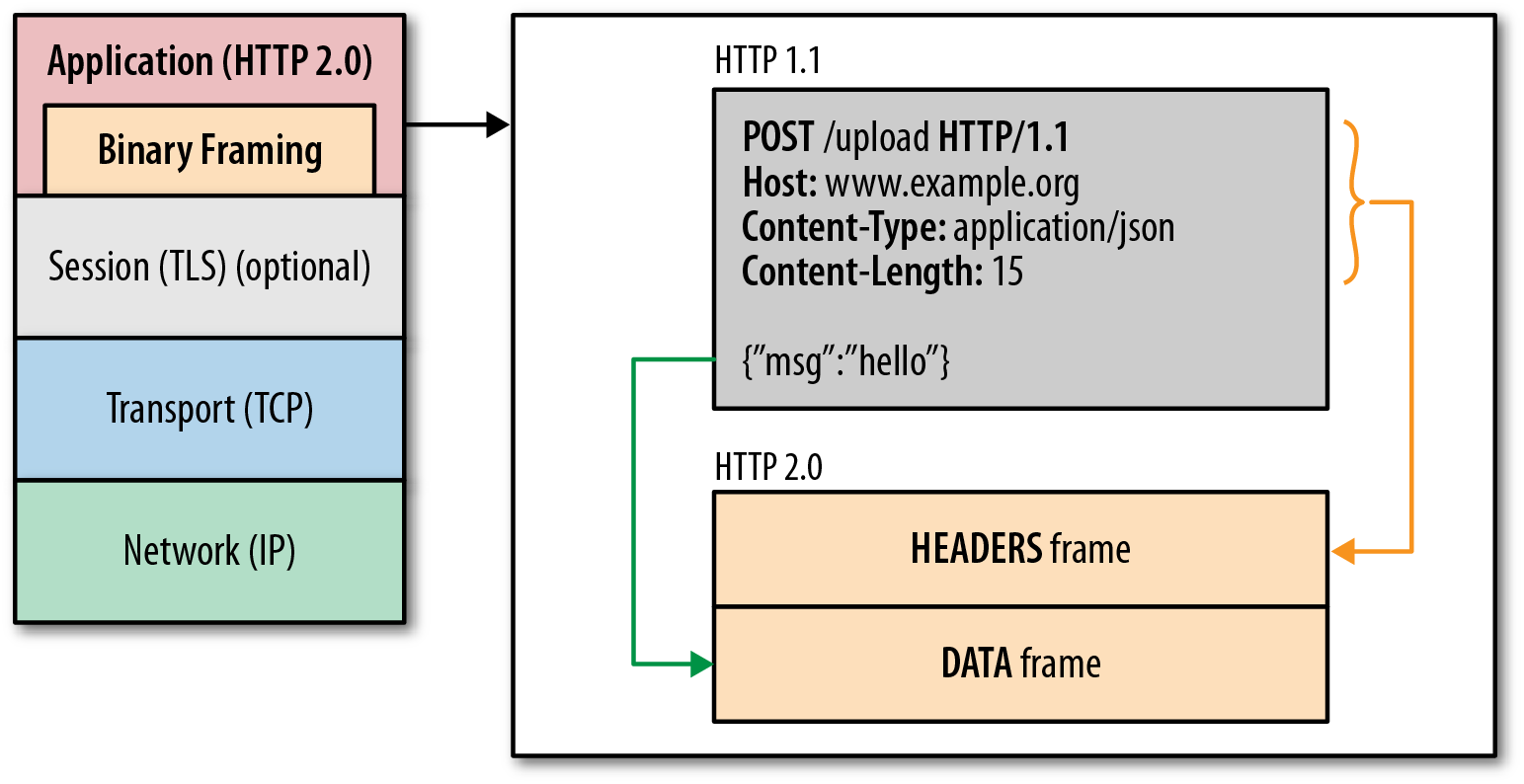
Binary Framing Layer
HTTP/2.0의 성능 향상과 확장을 담당하는 레이어이다. 위에서 언급한 것처럼 HTTP/1.X의 확장적 개념으로 도입되기 위해서 기존 애플리케이션 레이어에 별도로 추가된 새로운 레이어이다. 이 레이어에서는 클라이언트와 서버 사이 HTTP 메시지가 HTTP/2.0 방식으로 캡슐화 된 것인지 확인하고 변환해준다.
출처: Oreilly
위 그림처럼 애플리케이션 레이어에서 바이너리 인코딩 및 디코딩을 담당한다. HTTP/1.X에서 Plain Text를 사용해 \n을 기준으로 작성하는 프로토콜이라면, HTTP/2.0에서는 프레임이라고 불리는 바이너리 포맷으로 전송된다. 따라서 HTTP/2.0을 사용하려면 클라이언트와 서버 모두 애플리케이션 레이어에 Binary Framing Layer를 지원하고 있어야 한다.
이렇게 새로운 레이어 도입이 필수적이라는 측면에서 기존 인프라와 Incompatible 하기 때문에 HTTP/1.2가 될 수 없다.
HTTP/1.1 버전의 헤더 (메소드, 상태 코드, URI 등)은 그대로 유지하기 때문에 애플리케이션 레벨에서는 변경점이 필요 없다. Binary Framing Layer를 양측에 도입하기만 하면 HTTP/2.0으로 동작할 수 있다는 뜻이다.
Stream, Message, Frame
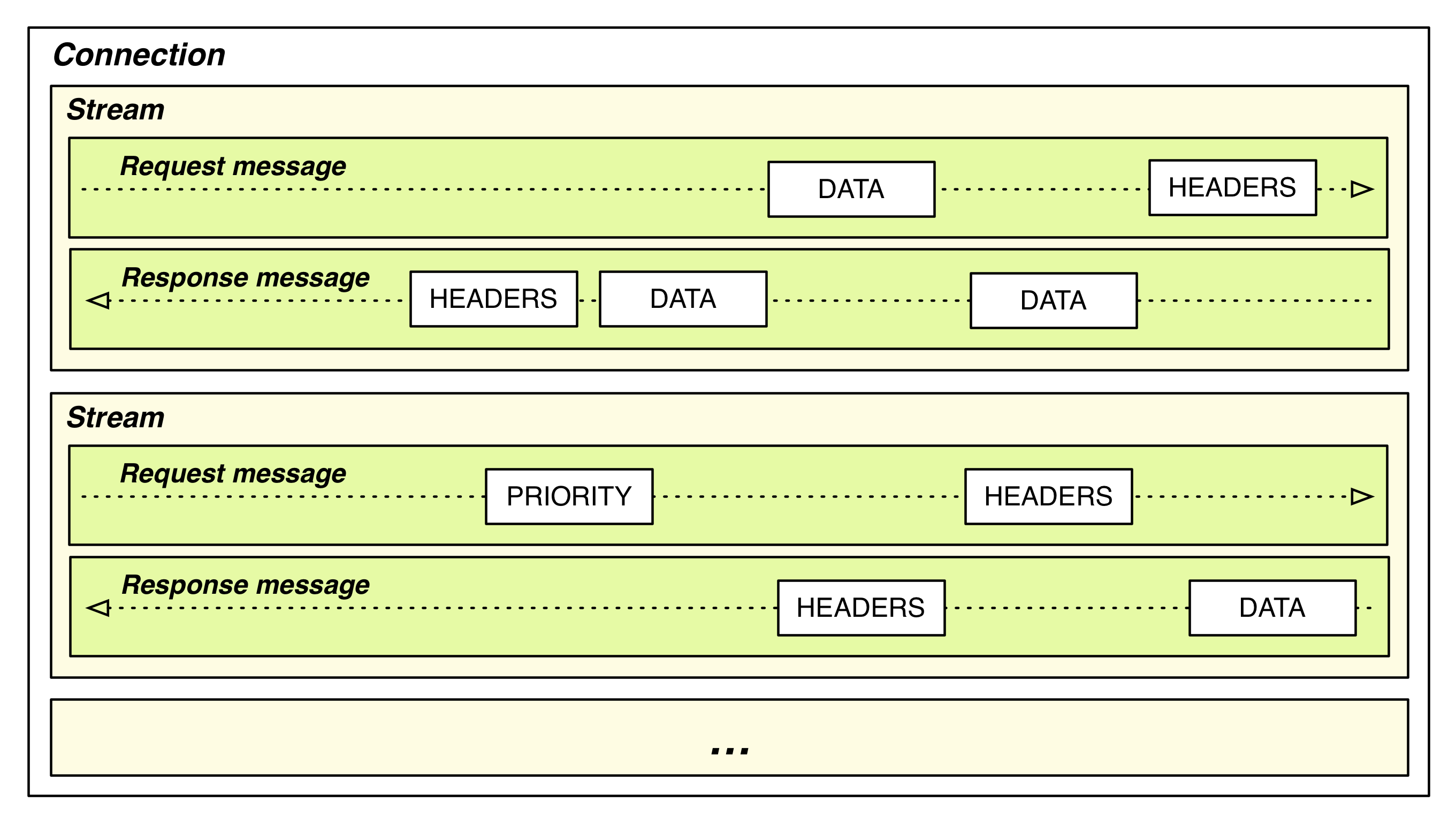
HTTP/2.0은 바이너리로 인코딩된 프레임을 주고받는다. 커뮤니케이션에 사용되는 컴포넌트들은 아래와 같다.
- Frame(프레임): HTTP/2.0 커뮤니케이션의 가장 작은 유닛이다. 각 프레임은 하나의 프레임 헤더와 바디가 있는데, 헤더에는 자신이 속한 Stream의 식별자 정보와 우선순위 정보가 있다. 이 프레임들은 Message를 구성하는 일부이거나 전체이다.
- Message(메시지): 온전한 메시지 시퀀스이다. 이 메시지는 논리적으로 HTTP/1.X 버전의 요청 또는 응답의 메시지와 같다.
- Stream(스트림): 성립된 TCP 컨넥션 위에서 양방향 바이트 플로우를 보낼 수 있는 통로이다. 하나 이상의 메시지를 운반할 수 있다.
출처: Oreilly
모든 커뮤니케이션은 하나의 TCP 컨넥션 위에서 발생하고, 컨넥션은 양방향 스트림 몇 개든 동작시킬 수 있다. 각 스트림은 유니크한 식별자가 있고, 추가적으로 우선순위에 대한 정보가 있다. 그리고 해당 정보들은 메시지를 전달할 때 메시지를 구성하는 각 프레임 헤더에 담기게 된다.
Google이 병렬 처리를 더 잘하도록 만드는 방법으로 기존 자원을 더 작게 나눠 관리하는 레이어를 추가해주는 방법을 많이 사용하는 것 같다는 생각을 했다. Go의 Goroutine도 Thread를 나눠 사용함으로써 더 가볍게 병렬로 동작하는 구현을 했다고 느꼈는데, 이 방법도 기존 컨넥션 활용을 더 작은 단위의 스트림이라는 단위로 나눠 사용하는 것이라고 느꼈다.
본인이 이해한 느낌은, 실제 구현 레벨에서는 컨넥션으로 전달되는 데이터는 Frame이다. 나머지는 논리적으로만 Binary Framing Layer에서 처리를 한다. 기존에 텍스트 메시지를 전달하듯, 메시지 순서와 상관 없이 메시지를 프레임으로 나눠 전송하는 형태이다. 그런데 도착해서는 프레임 헤더의 Stream 식별 정보로 데이터를 재조립할 수 있다.
gRPC가 HTTP/2.0을 활용한 방법
gRPC는 HTTP/2.0을 구현하면서 확장적으로 사용하고 있다. gRPC에서 사용하고 있는 커뮤니케이션을 위한 컴포넌트는 다음과 같다.
- Channel(채널)
- RPC
- Message(메시지)
위 HTTP/2.0처럼 각 컴포넌트들은 포함 관계를 가지고 있다. 채널은 여러 RPC를 가질 수 있고 RPC는 여러 메시지를 가질 수 있다.

묘하게 연결되는 구석들이 느껴지긴 하는데 구체적으로 다음 그림처럼 표현할 수 있다.
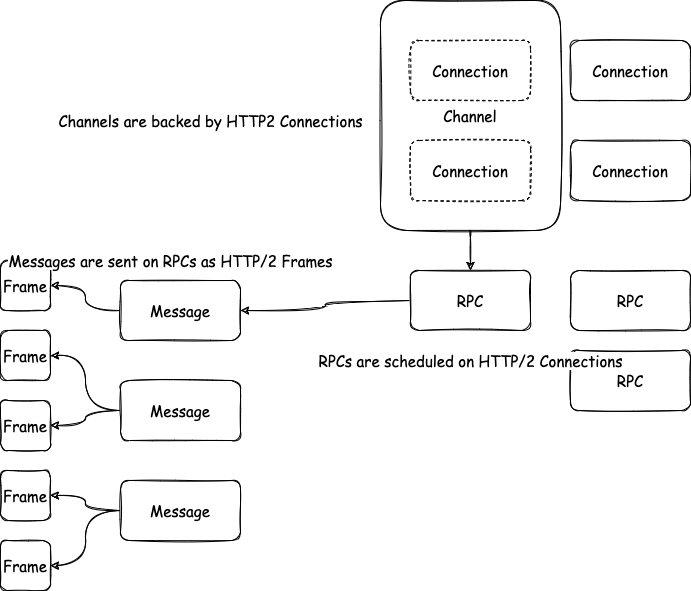
채널들은 gRPC에서 핵심적인 컨셉이다. HTTP/2.0에서 Stream 여러 개를 하나의 컨넥션 위에서 동작시킬 수 있었는데, gRPC의 채널은 컨넥션을 여러 개 활용해서 마치 하나의 전송 통로처럼 사용하도록 추상화하고 있다. 이 부분이 구체적으로 어떻게 구성되고 있는지는 후술하고 있다. 아무튼, 표면적으로는 RPC를 올리는 하나의 간단한 인터페이스를 제공하는 것 같지만 이면에는 여러 컴포넌트들이 여러 컨넥션을 묶어 Alive 상태를 유지한다. 즉, 채널은 하나의 엔드포인트와 연결해주는 가상의 컨넥션이다.
RPC는 이 컨넥션과 함께 본인이 해야 할 일을 수행한다. 해야 할 일이라고 하면 요청을 처리해 응답을 보내주는 역할을 하는 것인데, 커뮤니케이션 입장에서는 메시지를 주고받는 역할을 의미한다. RPC는 실제로 단순히 Stream 형태로 구현된다.
메시지는 HTTP/2.0의 메시지와 동일하고 RPC를 통해 전송된다. 조금 더 구체적으로는 프레임에 메시지를 “적재”하는 방법으로 동작한다.
약간 프레임을 경제적으로 사용한다는 느낌인 것 같다.
layered한다고 표현을 하는데, 프레임이 하나 이상의 메시지를 담을 수도 있고, 만약 메시지가 HTTP/2.0 스펙상 기본 프레임 사이즈인 16KB보다 크면 두 개 이상의 프레임을 사용할 수도 있다는 내용이었다.
정리하자면, Channel은 Connection(복수의 컨넥션을 추상화), RPC는 Stream, Message는 Message와 연결되는 개념이다.
Resolver & Load Balancer
채널이 결국 여러 컨넥션을 활용하고 있는 가상의 컨넥션인데, 어떻게 컨넥션들을 관리하고 유지하고 있을까? 이를 위해서 여러 컴포넌트들이 사용되는데 핵심적으로 name resolver(resolver, 리졸버), load balancer(로드 벨런서)이다. 리졸버는 DNS 리졸버로부터 호스트 이름을 가지고 IP 주소를 질의한 다음 넘겨받은 IP 주소 리스트를 로드 벨런서에게 넘겨주는 역할을 한다.
로드 벨런서는 넘겨받은 주소들을 가지고 컨넥션들을 만들어 하나의 채널로 구성한다. 그리고 RPC가 채널에 들어오면 정해진 로드 벨런스 전략에 따라 RPC를 실제 컨넥션에 연결해준다. 일단 22년 2월 기준으로 기본은 Round Robin 방식인 것 같고 다른 방식으로는 pick_first 방식이 있다. 이 링크에서 로드 벨런싱을 설정하는 예시를 볼 수 있다.
Channel과 유관한 코드들은 다른 언어에서는 Channel이라는 키워드를 쓰고 있는 것 같은데, Go에서는 이미 채널이라는 개념이 언어 레벨에 있다 보니,
ClientConn이라는 이름을 사용하고 있다. 동작 관련된 내용을 보면 클라이언트에서 찾아볼 수 있겠구나라고 생각할 수 있고, 예시 역시 클라이언트 코드를 보면 확인할 수 있다.
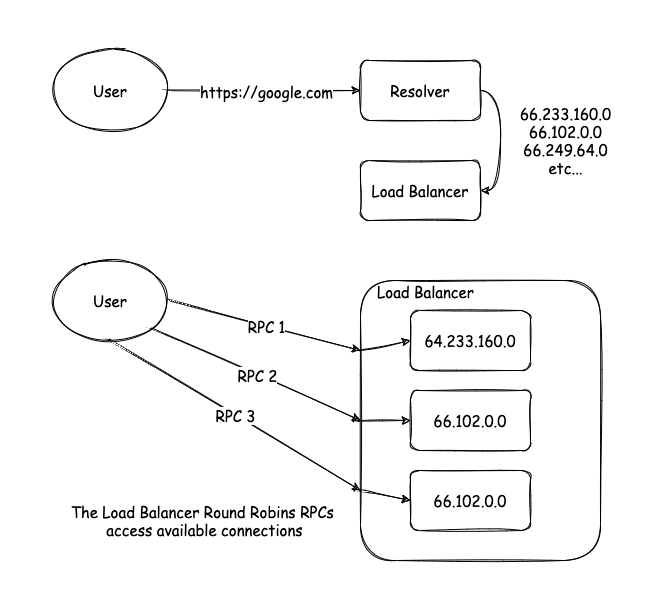
예를 들어서, DNS 리졸버로부터 호스트에 대한 13개의 IP 주소를 알려줬다면, 라운드 로빈 벨런서가 13개의 컨넥션을 만들고 RPC를 배분해준다.
Connection Management
한 번 설정된 이후 gRPC는 리졸버와 로드 벨런서에 의해 정의된 대로 컨넥션 풀을 유지하게 된다. 그렇다면 컨넥션 실패를 경험하면 어떻게 될까? 일단 실패를 인지하는 단계가 있어야 하지만 구체적으로 어떻게 실패를 인지하는지는 나중에 얘기하고, 일단 실패를 발견하면 로드 벨런서는 현재 가지고 있는 주소 리스트를 기반으로 컨넥션을 새로 구성하려고 한다.
한편 리졸버는 호스트 이름의 주소 리스트를 새롭게 업데이트한다. 이유는 기본적으로 IP가 유동적인 개념이기도 하고, 특정 IP가 프록시 서버였다고 가정했을 때 이 서버에 문제가 생겨 내려간 상태라고 한다면 재시도를 할 필요 없기 때문이다. 이렇게 업데이트한 주소 목록을 다시 로드 벨런서에게 넘겨주면 로드 벨런서는 불필요한 컨넥션을 내리고, 필요한 컨넥션은 새롭게 만든다. 이런 방법으로 Long-live Connection을 안정적으로 유지되도록 한다.
실패한 컨넥션 찾기
컨넥션 관리 사이클의 시작은 실패를 인지하는 것부터라고 했다. 실패한 컨넥션은 다음과 같은 케이스가 있다.
- Clean Failure: 실패에 대한 커뮤니케이션이 상호 진행됨
- Less-clean Failure: 실패에 대한 커뮤니케이션이 진행되지 않음
첫 번째 케이스는 엔드포인트에서 의도적으로 컨넥션을 끊었을 때 발생할 수 있다. Graceful Shutdown이 진행 중이라든지, 타임아웃이 발생한 경우 그럴 수 있다. 이런 경우 TCP 레이어에서 FIN Handshake가 발생할 것이고, gRPC는 즉각 실패를 인지할 수 있다.
두 번째 케이스는 엔드포인트가 의도치 않게 죽었거나, 클라이언트에게 알리지 않고 종료한 케이스이다. 이 경우 클라이언트는 TCP 컨넥션 연결 유지를 최대 10분 동안 하고 있는다. 10분 동안 컨넥션의 사용 가능 여부를 판단하는 것은 말이 안되니까, gRPC는 HTTP/2.0의 Ping Frame을 사용해 이런 케이스를 판단한다. 다이얼 옵션 중 KeepAlive 옵션이 켜진 경우 gRPC는 주기적으로 HTTP/2.0 Ping Frame을 전송하는데, 이 프레임들은 HTTP/2.0의 흐름 제어 플로우에서 바이패싱(무조건 통과)된다. 그리고 컨넥션이 살아있는 경우만 응답을 받게 되므로, 만약 핑의 응답을 못 받으면 gRPC는 이를 실패로 인지한다.
두 케이스 모두 실패로 인지된 이후는 위에서 설명한 대로 로드 벨런서의 재연결 시도가 시작된다.
KeepAlive옵션은 지금 버전 기준으로 기본값이 True인 것으로 알고 있다. 위에서 언급한 기능 외 추가적으로 장점이 있는데, 프록시들에게 컨넥션의 라이브니스(Liveness)를 알려주는 용도로 많이 사용된다. 만약 서버와 클라이언트 사이 프록시 서비스가 사용되고 있을 때, 많은 프록시 서비스들이 일정 시간 동안 사용되지 않은 컨넥션을 불필요한 것으로 간주하고 닫아버린다. 예를 들어서 AWS ELB 서비스는 TCP 컨넥션이 1분간 사용되지 않으면 해당 컨넥션을 닫고, GCP의 경우 10분이면 닫는다고 한다.KeepAlive옵션은 위에서 언급한 Ping을 보내는 방식으로 프록시 호스트에게 컨넥션이 사용 중임을 알리는 역할도 한다.
CORE 2: Protocol Buffer
지금까지 gRPC가 어떻게 HTTP/2.0을 활용하는지 얘기해봤다. 이제는 gRPC가 바디 사이즈를 줄이기 위해 활용한 바이너리 인코딩 메커니즘인 Protocol Buffer에 대해 얘기해보려고 한다.
프로토콜 버퍼는 구조화된 데이터를 바이너리로 직렬화하기 위한 구글의 메커니즘이다. 어떻게 사용하지에 대한 내용은 이 글에서 담지 않았다. 기본적인 얘기를 하자면 proto 확장파일을 가진 IDL을 정의한 다음 필요에따라 각 언어로 컴파일함으로써 쉽게 직렬화·역직렬화를 할 수 있는 Stub을 생성해 사용하는 구조이다.
메시지 구조
1 | message Example { |
메시지 구조는 이렇게 생겼다. int32 id = 1;이라는 라인에서 int32에 해당하는 부분이 필드 타입, id에 해당하는 곳이 필드(필드 이름), 1에 해당하는 부분을 필드 넘버라고 한다.
어떤 글에서는 필드 넘버를 필드 아이디라고도 하고… 조금씩 표현이 다른 것 같다. 아무튼 이 글에서는 이렇게 표기하고 있다.
필드 넘버는 유니크한 값이다. 실제 인코딩 디코딩 시점에서 Key 역할을 하기 때문이다. JSON 타입은 문자열로 구성된 타입을 키로 사용하지만 Protocol Buffer는 간단히 숫자로만 표현한다. {"id": Value}를 {1: Value}로 변환하는 느낌으로 보면 된다. 디코딩하는 시점에서는 개발의 편리를 위해 설정된 필드 이름으로 매핑된다. 이렇게 전송 과정에서 불필요한 텍스트를 다 버려 일차적으로 압축되는 효과가 있다.
인코딩
프로토콜 버퍼 사이즈가 줄어들게 되는 이유로 가장 길게 설명하는 부분은 Varints이다. Varints라고 표현하는 이 인코딩 방법은 스칼라 정수형 값을 인코딩하는 방법이다. 이 방법은 정수를 하나 이상의 유동적인 바이트 수로 표현한다. 숫자가 더 작을 수록 더 적은 바이트만 사용하게 된다.
인코딩된 바이트의 첫 번째 비트는 MSB(Most Significant Bit)라고 한다. 이 비트는 현재 바이트가 마지막 바이트인지 알려주는 역할을 한다. 나머지 7비트는 숫자를 표현하기 위해 사용한다.
인코딩은 2진수의 작은 숫자 비트부터 시작해서 위로 7비트를 잘라 표현하는 리틀 엔디안 방식이다. 예를 들어 1을 인코딩하면 다음과 같다.
1 | 0000 0001 -> MSB = 1 & 나머지 비트로 1 표현 |
300을 표현해보자
1 | 1010 1100 / 0000 0010 |
1010 1100과 0000 0010 두 개의 바이트로 표현된다. 먼저 앞의 바이트의 MSB가 1이기 때문에, 그 뒤 바이트 역시 같은 수를 표현하기 위해 사용되었다는 것을 의미한다. 그리고 그다음 바이트의 MSB가 0이니까 그다음 바이트에서 끝나는 수이다.
두 바이트의 뒤 7비트를 뒤집어서 합쳐주면 원래 숫자가 나온다. (앞의 7비트가 더 아랫자리 수니까 뒤집어서 합친다)
1 | 000 0010 ++ 010 1100 = 0001 0010 1100 = 256 + 32 + 8 + 4 = 300 |
이 방법은 사실 신박한 프로토콜 버퍼의 인코딩 방법이 아니라 과거에서부터 사용되던 압축 방법이다. “대규모 시스템을 지탱하는 기술”이라는 책에서 이 방법을
vbcode라는 이름으로 소개하고 있다. 과제로도 있어서 구현한 적이 있다.
필드 타입 & 필드 넘버 인코딩
위 방법은 메시지 타입이 Varint 타입인 경우 적용되는 방법이다. “메시지 타입”은 Wire Type이라고 문서에서 말한다.
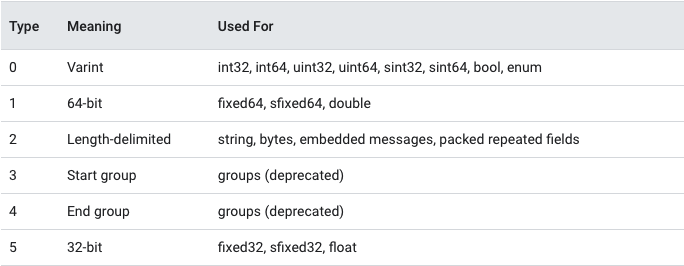
위 표처럼 Wire Type은 0부터 5까지 총 6개 정수형으로 구성되어있다. 이를 표현하는 건 3개의 비트만 있으면 되고, 필드 넘버도 위에서 설명했던 것처럼 정수형으로 인코딩되기 때문에 둘이 합쳐서 메시지의 맨 첫 번째로 나오게 된다.
즉, 데이터 스트림 시작의 첫 바이트는 MSB(1) + Field Number(4) + Wire Type(3)으로 구성되어있다.
따라서 필드 넘버는 1 ~ 15까지의 숫자만 쓰는 것이 좋다. 그 이상 사용하게 되면 바이트를 추가로 써야 한다. 사실 1바이트 더 쓰는 게 뭐 그렇게 대수냐? 라고 생각할 수 있다. 그 말도 맞다고 생각하기 때문에 그냥 숫자 자체는 15이하로 쓰고 안되면 넘겨 쓰자는 정도로 이해하면 될 것 같다.
인코딩된 데이터를 받았는데 아래와 같이 생겼다고 가정해보자. 각 띄어쓰기로 구성된 부분이 바이트이고, 16진수로 표현된 숫자이다.
1 | 08 96 01 |
위 데이터 중 맨 앞부분의 바이트는 필드 정보를 나타내고 있다.
1 | 08 = 0000 1000 -> MSB = 0, MSB 제거 |
따라서, 필드 넘버가 1이고 값은 Varint 타입인 값에 150 (96 01을 Varint 방식으로 디코딩하면 150)이 들어온 데이터라고 인식하게 된다.
작은 음수 인코딩
음수가 나올 가능성이 확실히 있는 경우, 2의 보수 표현법으로 바이너리를 채우는 Varint 방식을 그대로 적용하면 불필요하게 너무 많은 바이트를 쓰게 될 수 있다. 특히 작은 숫자일 수록 1로 큰 수 쪽이 채워지기 때문에 그렇다.
이런 경우 sint(sint32, sint64)로 필드 타입을 설정하는 것이 효율성 측면에서 더 좋다. Signed Integer 타입은 음수값을 지그재그 인코딩으로 먼저 변환한 다음 Varint 인코딩을 수행한다. 지그재그 인코딩은 다음 표처럼 음수를 양수 사이사이에 껴두어 치환한 테이블을 가지고 인코딩을 하는 방식이다.
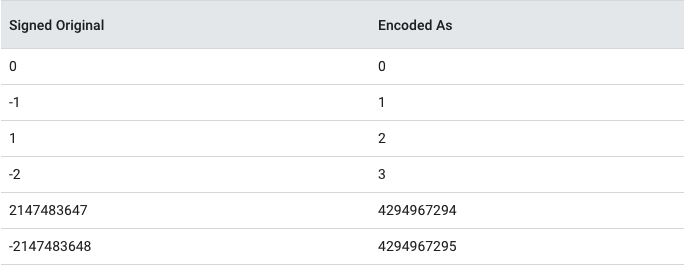
기타 다른 인코딩 방식은 단순히 필요한 바이트 길이를 미리 전달해주고 뒷부분을 바이트로 변환해 집어 넣는
length-delimited방식의 인코딩과,double,float처럼 고정된 바이트를 사용하는 경우 그대로 바이너리 값을 넣어주는 등, 큰 압축 효과 없이 데이터를 전달한다.
결론
지금까지 gRPC를 지탱하는 핵심 기술에 대해 알아봤다. 실제로 FAQ에는 “gRPC가 HTTP/2 위로 바이너리를 보내는 것보다 나은 게 있는가?”라는 질문이 있다. 이 질문에 결국 gRPC가 하는 역할은 크게 보면 그걸 하고 있다고 답변한다. 물론 결국 답변은 +a가 있기 때문에 더 낫다는 답변이지만, 본질적으로 우리는 핵심 두 가지를 살펴본 것이다.
어떻게 쓰는 것이 좋지?
그렇다면 gRPC는 앞으로 어떻게 써야 할까? 우선 HTTP/2.0이라는 특징과, 구체적으로 어떻게 구현해 사용하고 있는지를 알게 되었으니 Dial 옵션을 더 꼼꼼하게 알아볼 필요가 있다. 우리 상황에 맞게 더 잘 쓸 수 있는 방법이 있을지 확인해보고 프로젝트 환경에서 컨넥션을 효율적으로 사용할 수 있는 옵션이 무엇일지 찾아보고 적용해보면 좋을 것 같다.
그리고 Protocol Buffer를 사용하는 것 자체에서 주의해야 할 점 몇 가지가 있다. IDL에서 메시지에 새로운 필드를 추가하는 작업은 기본값 처리만 해두면 이전 시스템과 호환이 되기 때문에 비교적 자유롭게 추가할 수 있다. 그러나 삭제하는 작업은 고민해볼 필요가 있다. 삭제 자체는 문제 되지 않지만, 만약 삭제한 다음 해당 필드 넘버로 새로운 필드를 추가한다면, 과거 IDL을 사용하고 있던 시스템과 문제를 일으킨다. 따라서 값을 지울 때는 미래에도 이 값을 사용하지 않도록 키워드로 DEPRECATED 처리를 하든, reserved 키워드로 방어하든 조금 보수적으로 접근할 필요가 있다.
살짝 언급했지만, 프로토콜 버퍼에서 값이 없는 필드는 디코딩할 때 제로값(기본값)을 사용한다. 따라서 실제 값인지, 기본값인지 판단할 수 있는 로직이 필요하고 만약 그게 어렵다면 WKT의 Wrapper를 사용해 null (Go 에서는 nil) 타입이 제로값으로 들어가도록 한 번 감싸주는 것도 좋은 방법이 될 수 있다.
IDL을 관리해야한다는 이슈도 있다. 보통 프로토콜 버퍼를 사용하는 조직은 전사적인 IDL 관리를 진행하고 있다는 얘기를 많이 들었다. 뱅크샐러드글에서도 그 내용이 나온다. IDL 관리, 버저닝 등 미리 팀과 얘기해볼 것들이 많이 있다.
REST API는 대체되는가?
결론 먼저 말하면 당연히 아니다. REST API에 비해 결론적으로 갖게 되는 장점은 다음과 같은 것들이 있을 수 있다.
- TCP 컨넥션 사용 효율성 증가
- 메시지 Header 압축으로 네트워크 사용 감소
- Long-live Connection으로 Handshake Overhead 감소
- 페이로드 압축률 증가
그러나 클라이언트와 서버 모두 gRPC가 애플리케이션 레이어 앞쪽에서 동작해야 하는 영역이 있기 때문에, 그 부분을 자유롭게 손볼 수 없다면 사용이 어렵다. 대표적으로 Web 클라이언트는 온전히 gRPC 스텁을 동작시키지 못하기 때문에 HTTP/1.1에서 동작하는 방식으로 다운그레이딩되어 사용된다. 위에서 말한 장점들 역시 온전히 가져가지 못할 것이고, 그렇다면 굳이 그 환경에서도 gRPC를 써야 할지 의문이다.
프로토콜 버퍼의 공식문서를 보면 프로토콜 버퍼는 큰 데이터를 다루기에는 부적합한 방법이라고 설명한다. 메시지가 메가바이트 단위라면 다른 대안을 찾을 것을 권고하고 있다. 아마 인코딩 디코딩의 CPU Bound가 문제가 되는 것인가 싶다. 예를 들어 이미지 파일의 경우 스트림을 통해 보내주는 케이스가 있을 수도 있는데, 그냥 저장하고 있는 CDN 링크를 요구사항에 맞게 보내주는 것이 한 방법이 될 수 있다.
Reference
gRPC를 지탱하는 기술